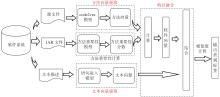
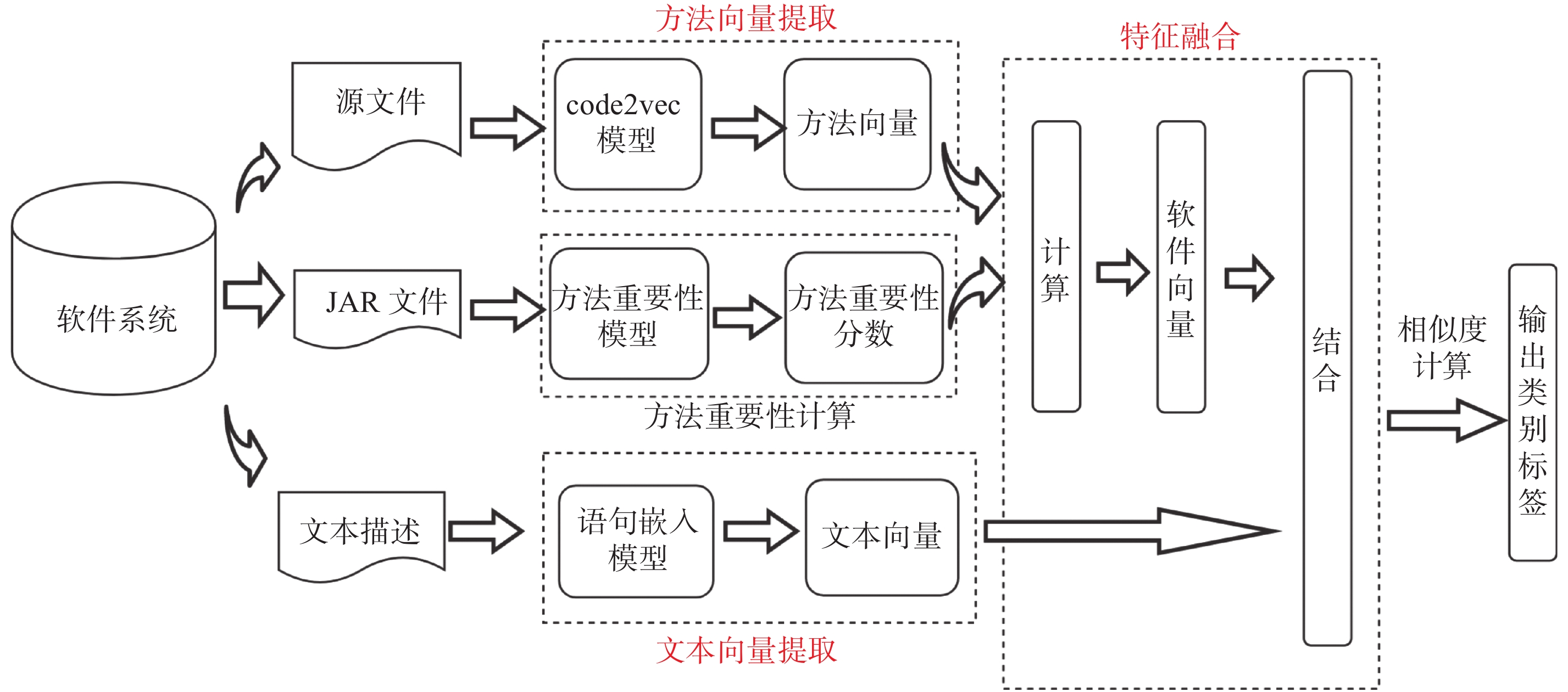
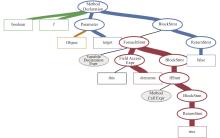
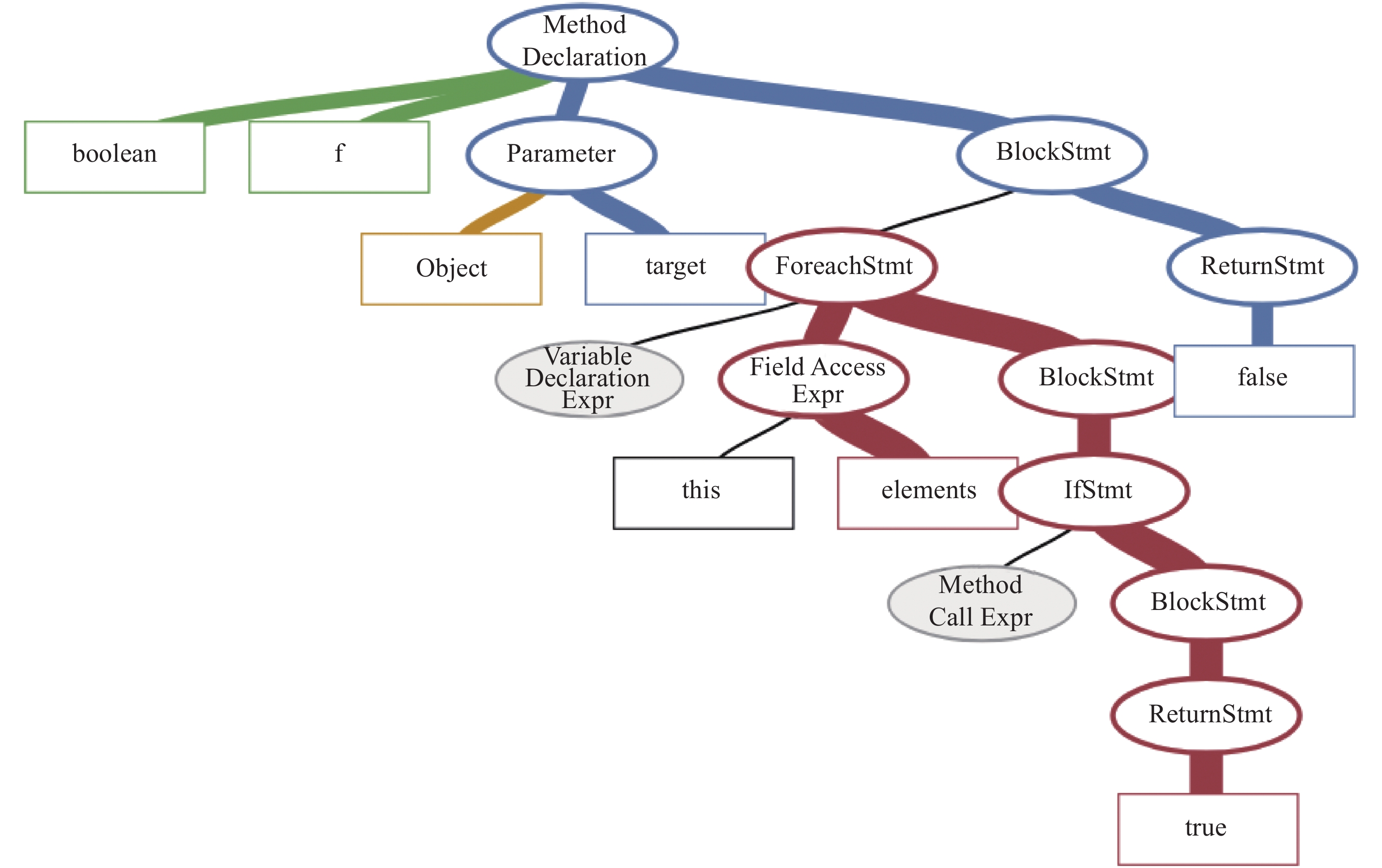
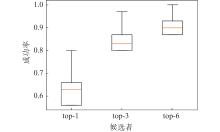
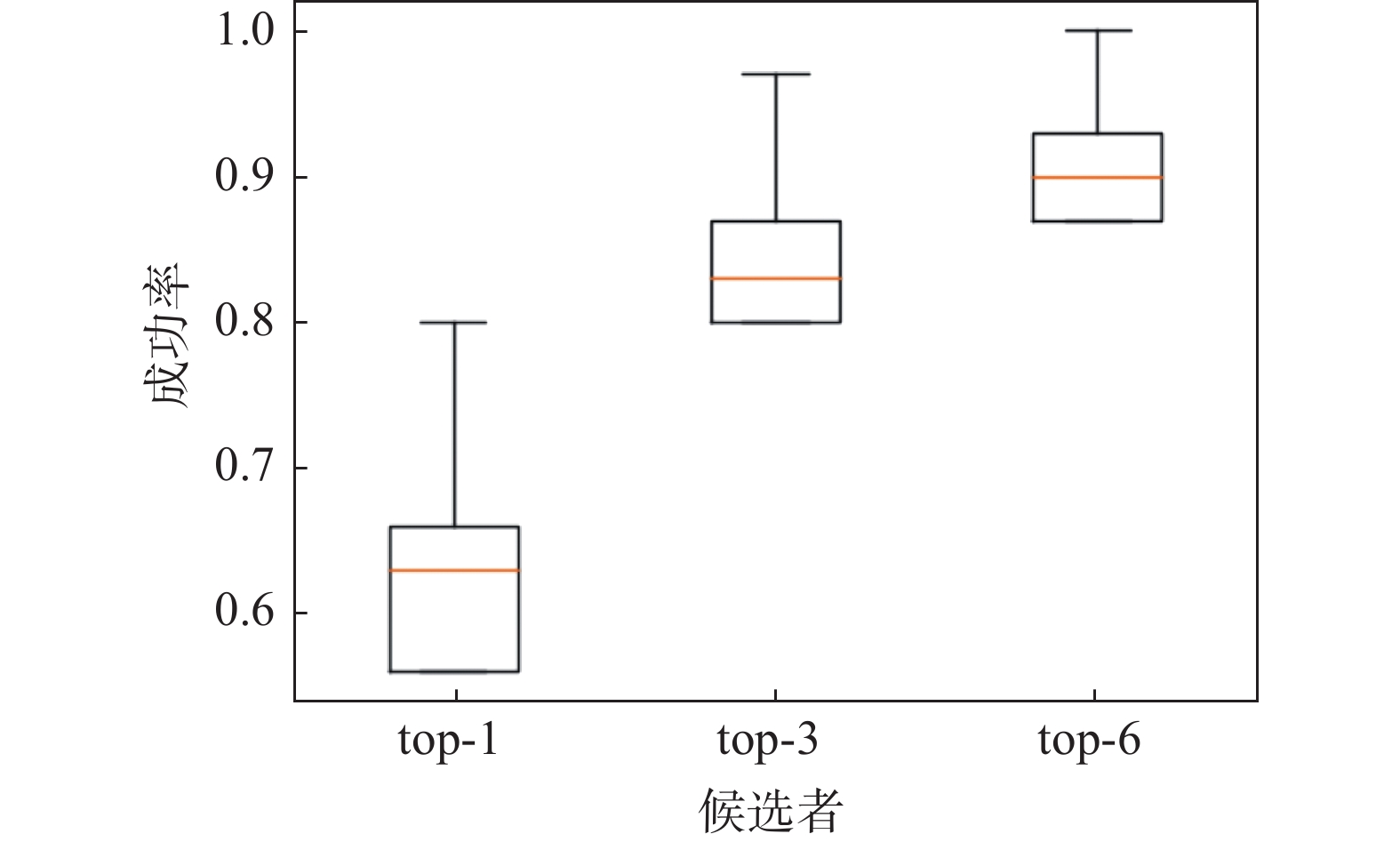
| 1 |
SHARMA A, THUNG F, KOCHHAR P S, et al. Cataloging github repositories [C]// Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering. ACM, 2017: 314-319.
|
| 2 |
WANG T, WANG H M, YIN G, et al.. Tag recommendation for open source software. Frontiers of Computer Science, 2014, 8 (1): 69- 82.
|
| 3 |
WANG Y, LIU H X, GAO S Q, et al. Categorizing npm packages by analyzing the text information in software repositories [C]// Proceedings of the 28th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 2021: 53-60.
|
| 4 |
Al-KOFAHI J M, TAMRAWI A, NGUYEN T T, et al. Fuzzy set approach for automatic tagging in evolving software [C]// Proceedings of the 2010 IEEE International Conference on Software Maintenance. IEEE, 2010. DOI: 10.1109/ICSM.2010.5609751.
|
| 5 |
RADOSAVLJEVIC V, GRBOVIC M, DJURIC N, et al. Smartphone app categorization for interest targeting in advertising marketplace [C]// Proceedings of the 25th International Conference Companion on World Wide Web. Geneva: International World Wide Web Conferences Steering Committee, 2016: 93-94.
|
| 6 |
YUSOF Y, ALHERSH T, MAHMUDDIN M, et al. Classification of machine learning engines using latent semantic indexing [C]// Knowledge Management International Conference (KMLCe). Kedah Darul Aman, Malaysia: Universiti Utara Malaysia (UUM), 2012: 472-476.
|
| 7 |
郑珏, 欧毓毅.. 基于卷积神经网络与多特征融合恶意代码分类方法. 计算机应用研究, 2022, 39 (1): 240- 244.
|
| 8 |
轩勃娜, 李进.. 基于改进 CNN 的恶意软件分类方法. 电子学报, 2023, 51 (5): 1187- 1197.
|
| 9 |
谷勇浩, 王翼翡, 刘威歆, 等.. 基于多重异质图的恶意软件相似性度量方法. 软件学报, 2023, 34 (7): 3188- 3205.
|
| 10 |
VARGAS-BALDRICH S, LINARES-VÁSQUEZ M, POSHYVANYK D. Automated tagging of software projects using bytecode and dependencies [C]// Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2015: 289-294.
|
| 11 |
YANG L, WANG L, HU Z G, et al. Automatic tagging for open source software by utilizing package dependency information [C]// Proceedings of the 2020 International Symposium on Theoretical Aspects of Software Engineering (TASE). IEEE, 2020: 137-144.
|
| 12 |
HAMEDNAI M R, KIM G, CHO S.. SimAndro: An effective method to compute similarity of Android applications. Soft Computing, 2019, 23, 7569- 7590.
|
| 13 |
LI M L, LU Q, LONG Y F. Representation learning of multiword expressions with compositionality constraint [C]// Knowledge Science, Engineering and Management, KSEM 2017, Lecture Notes in Computer Science, vol 10412. Cham: Springer, 2017: 507-519.
|
| 14 |
ALON U, ZILBERSTEIN M, LEVY O, et al.. code2vec: Learning distributed representations of code. Proceedings of the ACM on Programming Languages, 2019, 3 (POPL): 40.
|
| 15 |
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL].(2013-09-07)[2023-09-05]. https://doi.org/10.48550/arXiv.1301.3781.
|
| 16 |
COMPTON R, FRANK E, PATROS P, et al. Embedding Java classes with code2vec: Improvements from variable obfuscation [C]// Proceedings of the 2020 IEEE/ACM 17th International Conference on Mining Software Repositories (MSR). IEEE, 2020: 243-253.
|
| 17 |
LI H, WANG T, PAN W F, et al.. Mining key classes in Java projects by examining a very small number of classes: A complex network-based approach. IEEE Access, 2021, 9, 28076- 28088.
|
| 18 |
陶佩. 基于复杂网络的软件项目重要类识别研究[D]. 上海: 华东师范大学, 2022.
|
| 19 |
BRIN S, PAGE L.. The anatomy of a large-scale hypertextual Web search engine. Computer Networks and ISDN Systems, 1998, 30 (1/2/3/4/5/6/7): 107- 117.
|
| 20 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics (ACL), 2019: 4171-4186.
|
| 21 |
BROWN T, MANN B, RYDER N, et al.. Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020, 33 (1): 1877- 1901.
|
 )
)
 中文核心期刊
中文核心期刊