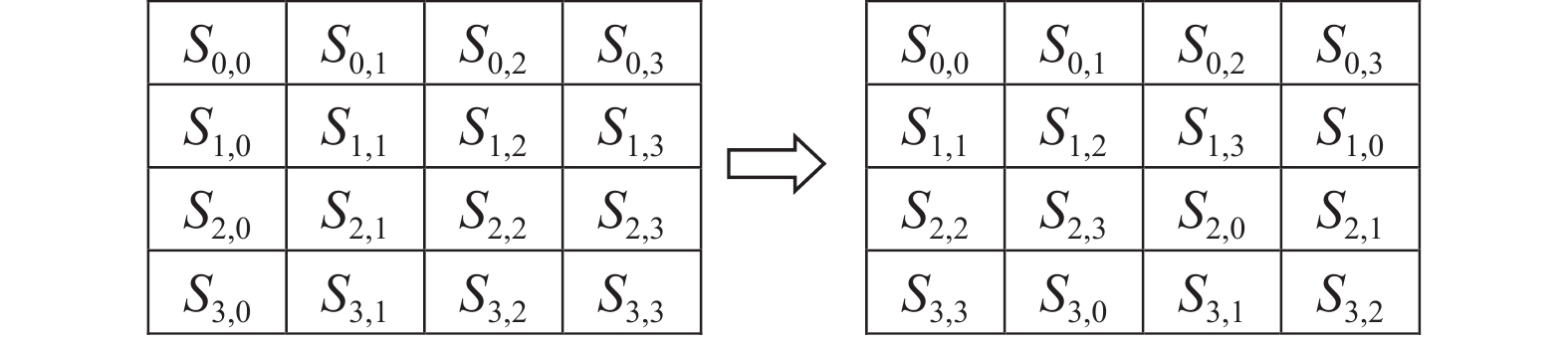
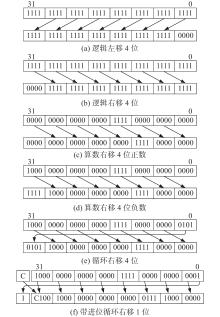
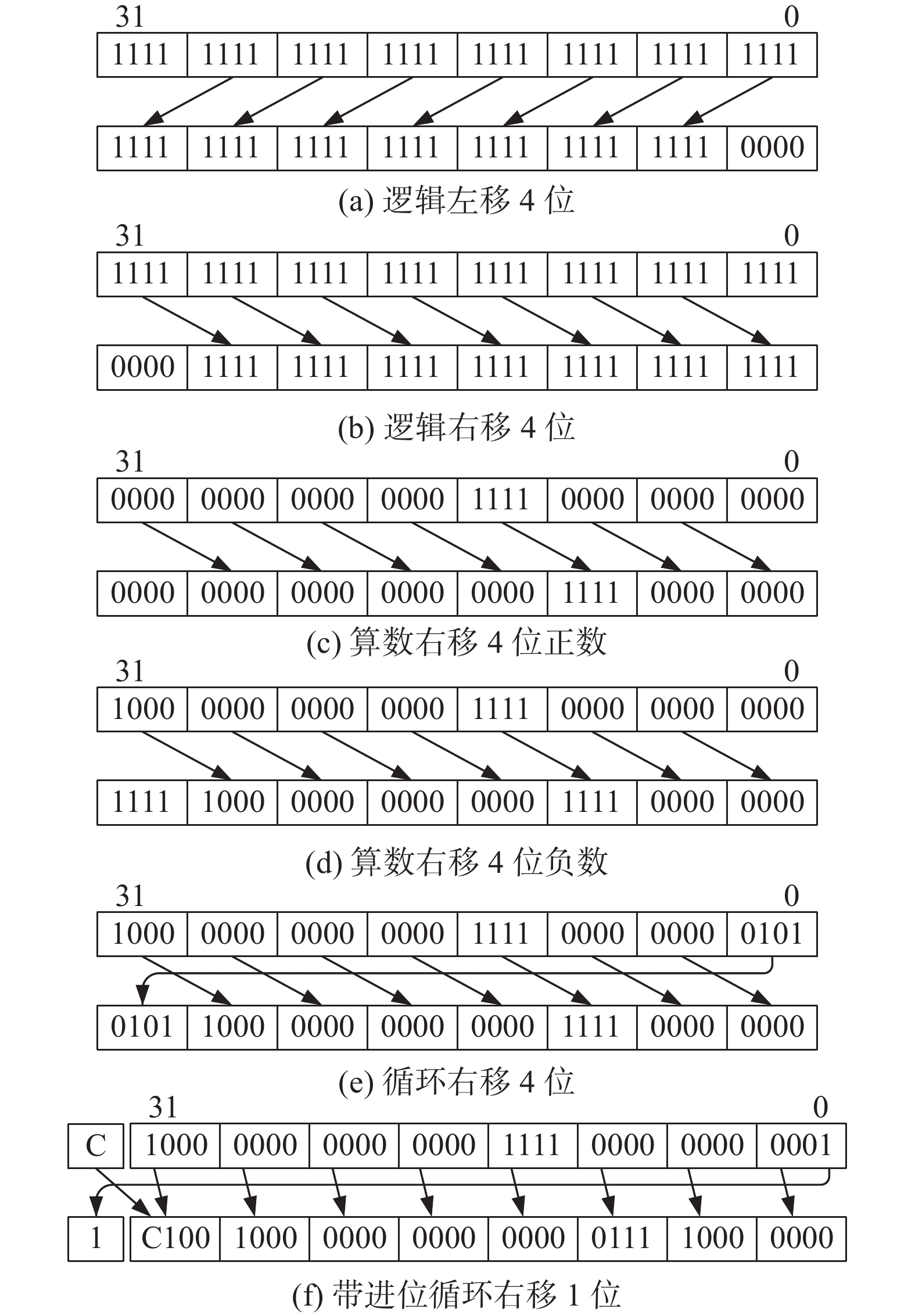
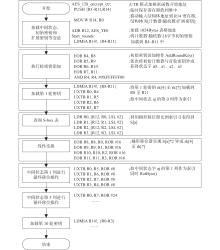
| 1 |
胡荣群, 罗杰. 嵌入式系统的安全分析. 计算机与现代化, 2007, (2): 93- 96.
|
| 2 |
徐绘凯, 刘跃, 马振邦, 等. MQTT 安全大规模测量研究. 信息网络安全, 2020, 20 (9): 37- 41.
|
| 3 |
陈颖, 陈长松, 胡红钢. SM4 硬件电路的功耗分析研究. 信息网络安全, 2018, (5): 52- 58.
|
| 4 |
尚文利, 尹隆, 刘贤达, 等. 工业控制系统安全可信环境构建技术及应用. 信息网络安全, 2019, (6): 1- 10.
|
| 5 |
LAU D. Secure bootloader implementation [EB/OL]. (2012-10-14)[2021-03-05]. https://www.nxp.com/docs/en/application-note/AN4605.pdf.
|
| 6 |
曾小波, 易志中, 焦歆. 基于 51 核的 AES 算法高速硬件设计与实现. 电子科技, 2016, 29 (1): 36- 39.
|
| 7 |
NASSER Y, BAZZOUN M A, ABDUL-NABI S. AES algorithm implementation for a simple low cost portable 8-bit microcontroller [C]//2016 Sixth International Conference on Digital Information Processing and Communications. 2016: 214-218.
|
| 8 |
章登义, 毛从武, 李永忠. AES 算法及其在 DSP 中优化实现. 计算机工程与科学, 2005, 27 (9): 7- 9.
|
| 9 |
LI Q J, ZHONG C W, ZHAO K Y, et al. Implementation and analysis of AES encryption on GPU [C]//2012 IEEE 14th International Conference on High Performance Computing and Communication & 2012 IEEE 9th International Conference on Embedded Software and Systems. 2012: 843-848.
|
| 10 |
张月华, 张新贺, 刘鸿雁. AES 算法优化及其在 ARM 上的实现. 计算机应用, 2011, 31 (6): 1539- 1542.
|
| 11 |
张小梅. AES 算法在 ARM 核嵌入式系统上的优化实现. 计算机应用与软件, 2012, 29 (5): 285- 288.
|
| 12 |
张金辉, 郭晓彪, 符鑫. AES 加密算法分析及其在信息安全中的应用. 信息网络安全, 2011, (5): 31- 33.
|
| 13 |
ATASU K, BREVEGLIERI L, MACCHETTI M. Efficient AES implementations for ARM based platforms [C]//Proceedings of the 2004 Association for Computing Machinery Annual Symposium on Applied Computing. 2004: 841-845.
|
| 14 |
DAEMEN J, RIJMEN V. AES proposal: Rijndael [EB/OL]. (1999-09-03)[2020-10-08]. https://csrc.nist.gov/csrc/media/projects/cryptographic-standards-and-guidelines/documents/aes-development/rijndael-ammended.pdf.
|
| 15 |
BIHAM E. A fast new DES implementation in software [C]//Proceedings of the 4th International Workshop on Fast Software Encryption. 1997: 260-272.
|
| 16 |
MATSUI M, NAKAJIMA J. On the power of bitslice implementation on Intel Core2 processor [C]//Cryptographic Hardware and Embedded Systems-CHES 2007. 2007: 121-134.
|
| 17 |
REBEIRO C, SELVAKUMAR D, DEVI A S L. Bitslice implementation of AES [C]//Proceedings of the 5th International Conference on Cryptology and Network Security. 2006: 203-212.
|
| 18 |
HAMBURG M. Accelerating AES with vector permute instructions [C]//Proceedings of the 11th International Workshop on Cryptographic Hardware and Embedded Systems. 2009: 18-32.
|
| 19 |
王子派. ARM 系列微处理器架构初探. 电子世界, 2016, (14): 56- 57.
|
| 20 |
BERNSTEIN D J, SCHWABE P. New AES software speed records [C]//Proceedings of the 9th International Conference on Cryptology in India: Progress in Cryptology. 2008: 322-336.
|
| 21 |
EMMANUEL B, HASSAN H. Extended Barrel-Shifter for versatile QC-LDPC decoders. IEEE Wireless Communications Letters, 2020, 9 (5): 643- 647.
|
| 22 |
DWORKIN M. Recommendation for block cipher modes of operation [C]//National Institute of Standards and Technology Special Publication. 2001: 800-38A.
|
| 23 |
AUSTIN T, BLAAUW D, MUDGE T, et al. Making typical silicon matter with razor. Computer, 2004, 37 (3): 57- 65.
|
| 24 |
HUNTER M. Optimizing performance on Kinetis K-series MCUs [EB/OL]. (2014-06-11)[2021-03-03]. https://www.nxp.com/docs/en/application-note/AN4745.pdf.
|
| 25 |
NIKOLAIDIS S, LAOPOULOS T. Instruction-level power consumption estimation of embedded processors for low-power applications [J]. Computer Standards & Interfaces, 2002, 24: 133-137.
|
 ), 张刚刚2,*(
), 张刚刚2,*( 中国综合性科技类核心期刊(北大核心)
中国综合性科技类核心期刊(北大核心)