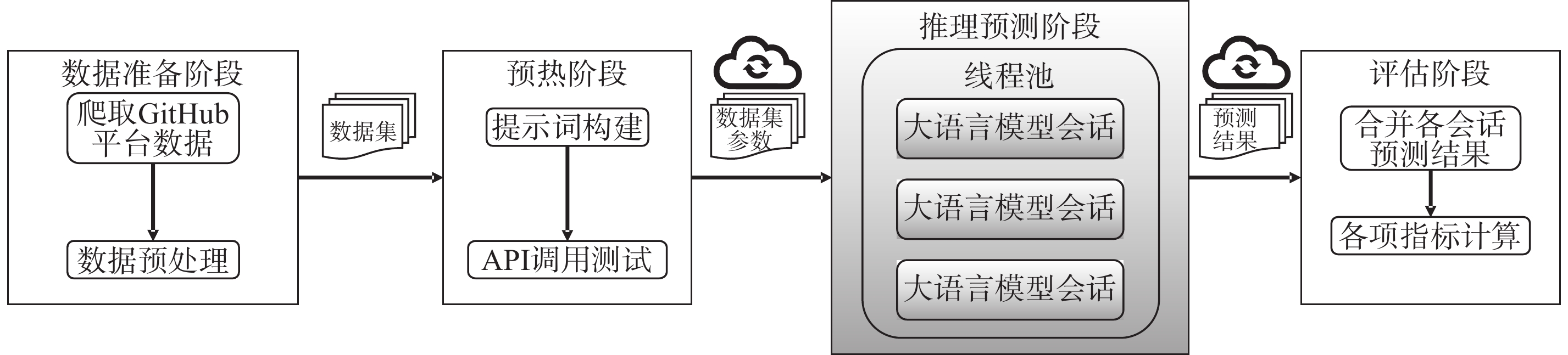
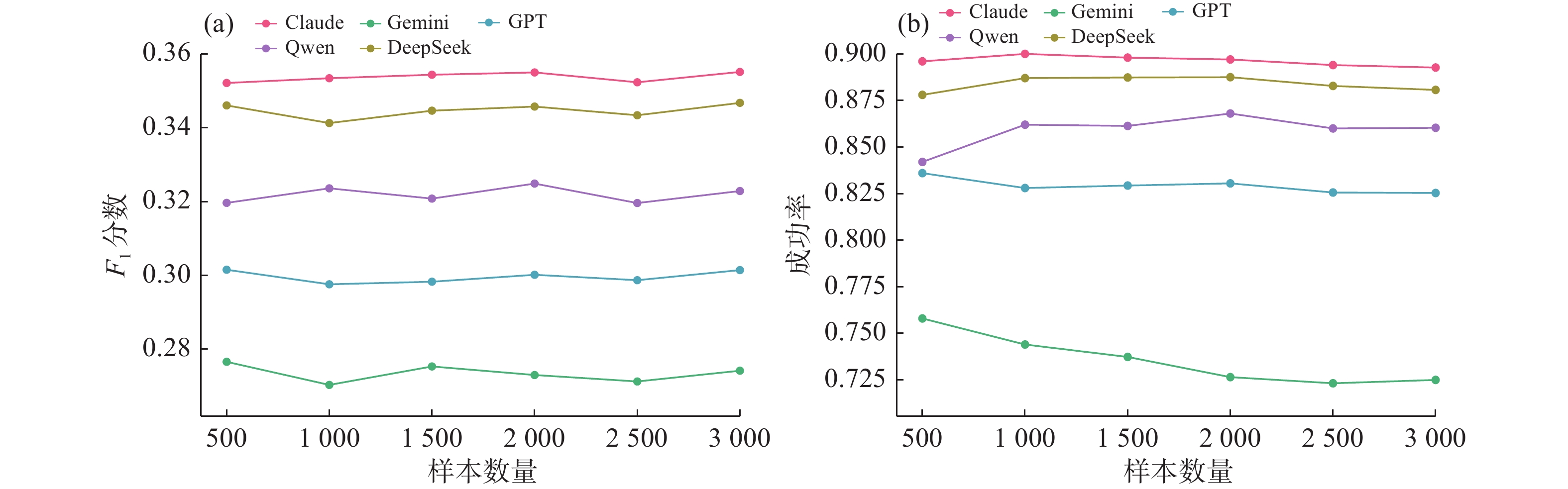
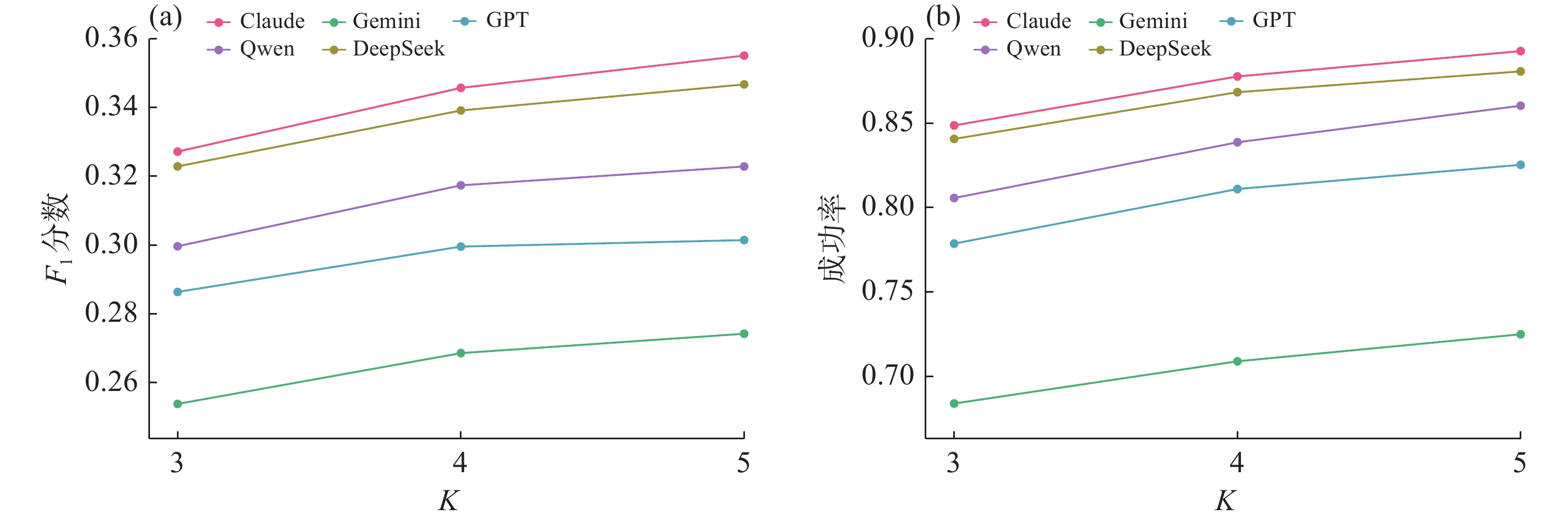
| 1 |
THUNG F, BISSYANDÉ T F, LO D, et al. Network structure of social coding in GitHub [C]// 2013 17th European Conference on Software Maintenance and Reengineering. IEEE, 2013: 323-326.
|
| 2 |
CHEN K Y, TORO-MORENO M, SUBRAMANIAM A R. GitHub is an effective platform for collaborative and reproducible laboratory research [EB/OL]. (2025-02-10)[2025-05-25]. http://arxiv.org/abs/2408.09344.
|
| 3 |
FORMAN G. BNS feature scaling: An improved representation over tf-idf for svm text classification [C]// Proceedings of the 17th ACM conference on Information and Knowledge Management. ACM, 2008: 263-270.
|
| 4 |
IZADI M, HEYDARNOORI A, GOUSIOS G.. Topic recommendation for software repositories using multi-label classification algorithms. Empirical Software Engineering, 2021, 26 (5): 93.
|
| 5 |
BASART S, DUBA S, FERRI C, et al. GPT-4 technical report [EB/OL]. (2024-03-04)[2025-05-25]. http://arxiv.org/abs/2303.08774.
|
| 6 |
SONODA Y, KUROKAWA R, NAKAMURA Y, et al. Diagnostic performances of GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro in “Diagnosis Please” cases [J]. Japanese Journal of Radiology, 2024, 42(11): 1231-1235.
|
| 7 |
ANIL R, BORGEAUD S, ALAYRAC J-B, et al. Gemini: A family of highly capable multimodal models [EB/OL]. (2025-05-09)[2025-05-25]. http://arxiv.org/abs/2312.11805.
|
| 8 |
Anthropic. Claude 3.7 Sonnet and Claude Code [EB/OL]. (2025-02-25)[2025-05-25]. https://www.anthropic.com/news/claude-3-7-sonnet.
|
| 9 |
LIU A X, FENG B, XUE B, et al. DeepSeek-V3 technical report [EB/OL]. (2025-02-18)[2025-05-25]. http://arxiv.org/abs/2412.19437.
|
| 10 |
YANG A, LI A F, YANG B S, et al. Qwen3 technical report [A/OL]. (2025-05-14)[2025-05-25]. http://arxiv.org/abs/2505.09388.
|
| 11 |
ZHAO S Y, XIA X Y, FITZGERALD B, et al. OpenRank leaderboard: Motivating open source collaborations through social network evaluation in Alibaba [C]// Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice. ACM, 2024: 346-357.
|
| 12 |
ZHANG J Q, SUN Y C, ZHOU Y Q, et al. Exploring GitHub topics: Unveiling their content and potential [C]// 2024 IEEE International Conference on Software Services Engineering (SSE). IEEE, 2024: 25-35.
|
| 13 |
DI ROCCO J, DI RUSCIO D, DI SIPIO C, et al.. HybridRec: A recommender system for tagging GitHub repositories. Applied Intelligence, 2023, 53, 9708- 9730.
|
| 14 |
KALLIAMVAKOU E, GOUSIOS G, BLINCOE K, et al. The promises and perils of mining GitHub [C]// Proceedings of the 11th Working Conference on Mining Software Repositories. ACM, 2014: 92-101.
|
| 15 |
BORGES H, HORA A, VALENTE M T. Understanding the factors that impact the popularity of GitHub repositories [C]// 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2016: 334-344.
|
| 16 |
KIM Y. Convolutional neural network for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 2014: 1746–1751.
|
| 17 |
JELODAR H, WANG Y L, ORJI R, et al.. Deep sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: NLP using LSTM recurrent neural network approach. IEEE Journal of Biomedical and Health Informatics, 2020, 24 (10): 2733- 2742.
|
| 18 |
FLORIDI L, CHIRIATTI M.. GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 2020, 30, 681- 694.
|
| 19 |
KOROTEEV M V. BERT: A review of applications in natural language processing and understanding [EB/OL]. (2021-03-22)[2025-05-25]. http://arxiv.org/abs/2103.11943.
|
| 20 |
ABBURI H, SUESSERMAN M, PUDOTA N, et al. Generative AI text classification using ensemble LLM approaches [EB/OL]. (2023-09-14)[2025-05-25]. http://arxiv.org/abs/2309.07755.
|
| 21 |
KUBLIK S, SABOO S. GPT-3: The Ultimate Guide to Building NLP Products with OpenAI API [M]. Birmingham, UK: Packt Publishing Ltd. , 2023.
|
| 22 |
XU B W, HOANG T, SHARMA A, et al.. Post2vec: Learning distributed representations of stack overflow posts. IEEE Transactions on Software Engineering, 2021, 48 (9): 3423- 3441.
|
| 23 |
WANG X Y, XIA X, LO D.. TagCombine: Recommending tags to contents in software information sites. Journal of Computer Science and Technology, 2015, 30 (5): 1017- 1035.
|
| 24 |
COSENTINO V, LUIS J, CABOT J. Findings from GitHub: Methods, datasets and limitations [C]// Proceedings of the 13th International Conference on Mining Software Repositories. ACM, 2016: 137-141.
|
 )
)
 中国综合性科技类核心期刊(北大核心)
中国综合性科技类核心期刊(北大核心)