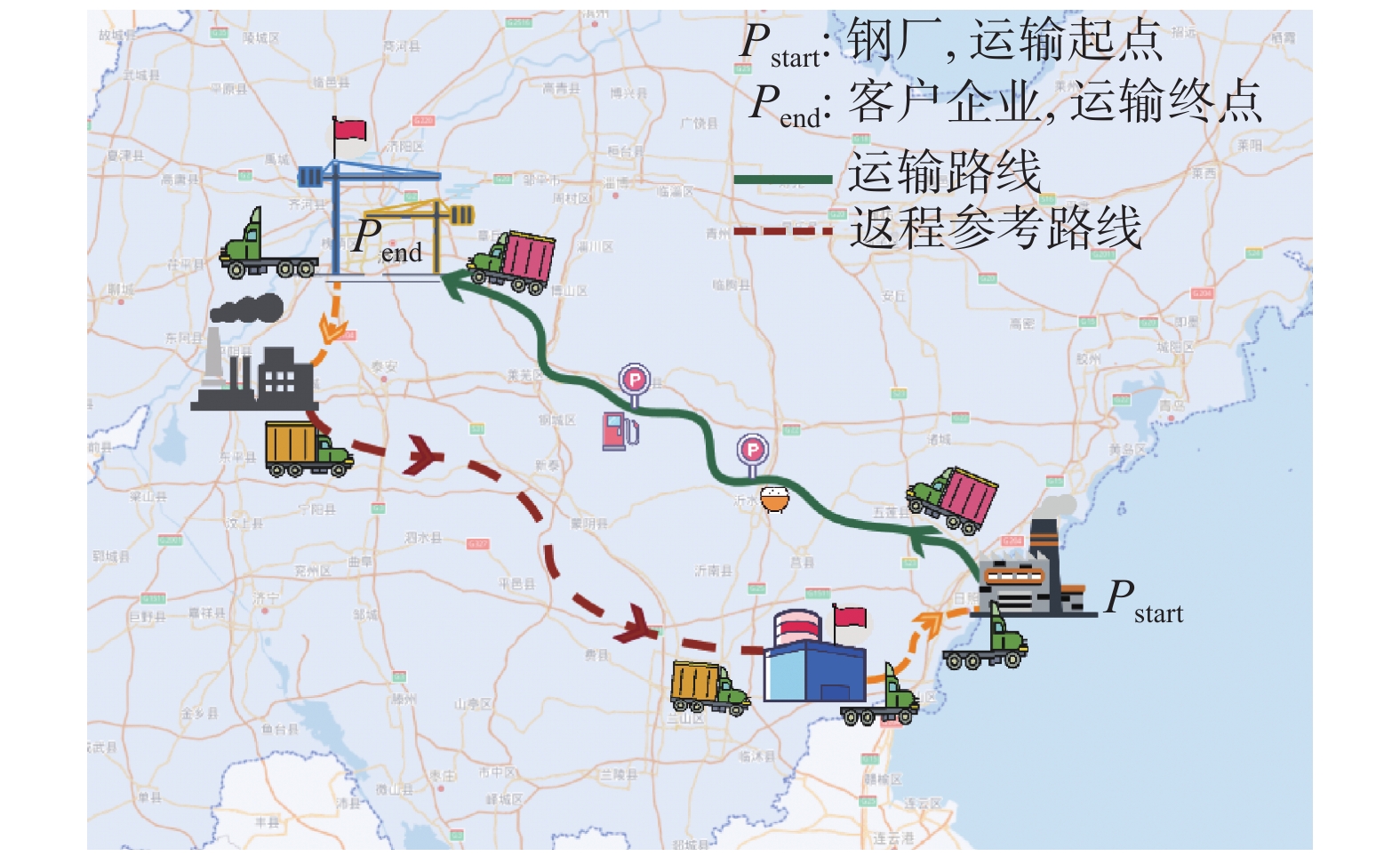
| 1 |
ZHOU W, YANG Y, ZHANG Y, et al. Deep flexible structure spatial-temporal model for taxi capacity prediction. Knowledge-Based Systems, 2020, 205, 106286.
|
| 2 |
WONG R C P, SZETO W Y, WONG S C. A two-stage approach to modeling vacant taxi movements. Transportation Research Procedia, 2015, (7): 147- 163.
|
| 3 |
JINDAL I, QIN Z W, CHEN X W, et al. A unified neural network approach for estimating travel time and distance for a taxi trip [EB/OL]. (2017-10-12)[2022-06-22]. https://arxiv.org/pdf/1710.04350.pdf
|
| 4 |
LI Y G, FU K, WANG Z, et al. Multi-task representation learning for travel time estimation [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2018: 1695-1704.
|
| 5 |
WANG H J, TANG X F, KUO Y H, et al. A simple baseline for travel time estimation using large-scale trip data. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10 (2): 19.
|
| 6 |
YANG Z C, YANG D Y, DYER C, et al. Hierarchical attention networks for document classification [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 1480-1489.
|
| 7 |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory. Neural Computation, 1997, 9 (8): 1735- 1780.
|
| 8 |
KAMARIANAKIS Y, PRASTACOS P. Space-time modeling of traffic flow. Computers and Geosciences, 2005, 31 (2): 119- 133.
|
| 9 |
CASTRO-NETO M, JEONG Y S, JEONG M K, et al. Online-SVR for short-term traffic flow prediction under typical and atypical traffic conditions. Expert Systems with Applications, 2009, 36 (3): 6164- 6173.
|
| 10 |
LESHEM G, RITOV Y. Traffic flow prediction using adaboost algorithm with random forests as a weak learner [J]. International Journal of Electrical and Computer Engineering, 2007, 2(2): 111-116.
|
| 11 |
ZHANG J B, ZHENG Y, QI D K. Deep spatio-temporal residual networks for citywide crowd flows prediction [C]// 31st AAAI Conference on Artificial Intelligence. 2017: 1655-1661.
|
| 12 |
WANG D, CAO W, LI J, et al. DeepSD: Supply-demand prediction for online car-hailing services using deep neural networks [C]// 2017 IEEE 33rd International Conference on Data Engineering (ICDE). IEEE, 2017: 243-254. DOI: 10.1109/ICDE.2017.83.
|
| 13 |
KE J T, YANG H, ZHENG H Y, et al. Hexagon-based convolutional neural network for supply-demand forecasting of ride-sourcing services. IEEE Transactions on Intelligent Transportation Systems, 2019, 20 (11): 4160- 4173.
|
| 14 |
JENELIUS E, KOUTSOPOULOS H N. Travel time estimation for urban road networks using low frequency probe vehicle data. Transportation Research Part B: Methodological, 2013, 53, 64- 81.
|
| 15 |
WANG Z, FU K, YE J P. Learning to estimate the travel time [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2018: 858-866.
|
| 16 |
YAN S, CHEN X, HUO R, et al. Learning to build user-tag profile in recommendation system [C]// Proceedings of the 29th ACM International Conference on Information & Knowledge Management. ACM, 2020: 2877-2884.
|
| 17 |
BENGIO Y, SIMARD P, FRASCONI P. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 1994, 5 (2): 157- 166.
|
| 18 |
WU C H, HO J M, LEE D T. Travel-time prediction with support vector regression. IEEE Transactions on Intelligent Transportation Systems, 2004, 5 (4): 276- 281.
|
| 19 |
BREIMAN L. Random forests. Machine Learning, 2001, 45 (1): 5- 32.
|
| 20 |
WANG D, ZHANG J B, CAO W, et al. When will you arrive? Estimating travel time based on deep neural networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2018: 2500-2507.
|
| 21 |
GUO G D, WANG H, BELL D, et al. kNN model-based approach in classification [C]// On the Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, OTM 2003, Lecture Notes in Computer Science, vol 2888. Berlin: Springer, 2003: 986-996.
|
| 22 |
朱军, 胡文波. 贝叶斯机器学习前沿进展综述. 计算机研究与发展, 2015, 52 (1): 16- 26.
|
| 23 |
FRIEDMAN J H. Greedy function approximation: A gradient boosting machine. Annals of Statistics, 2001, 1189- 1232.
|
| 24 |
王黎明, 王连, 杨楠. 应用时间序列分析 [M]. 上海: 复旦大学出版社, 2008.
|
 )
)
 中文核心期刊
中文核心期刊