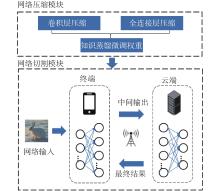
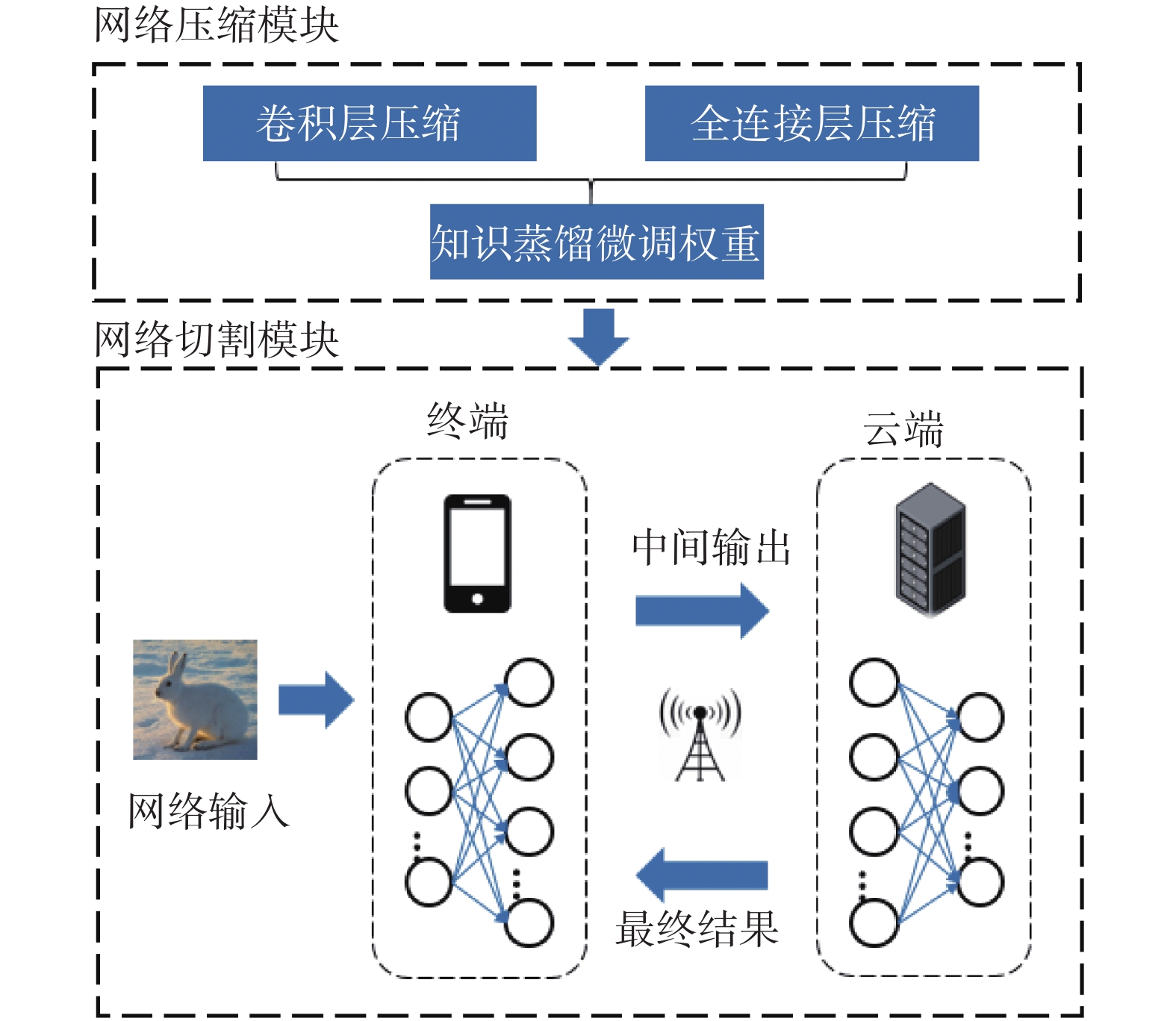
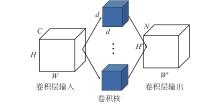
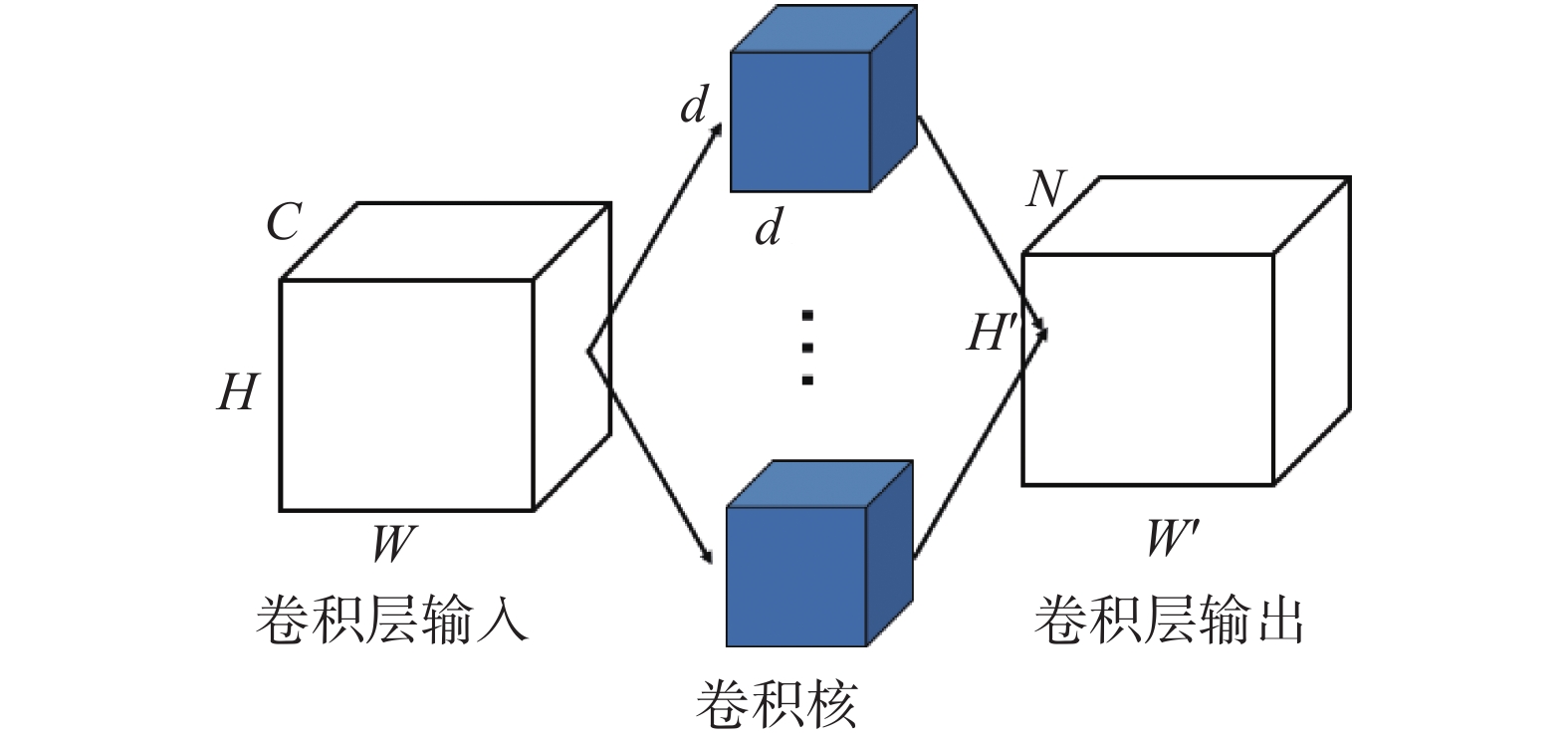
| 1 |
ESHRATIFAR A E, ESMAILI A, PEDRAM M. Towards collaborative intelligence friendly architectures for deep learning [C]// The 20th International Symposium on Quality Electronic Design (ISQED). 2019: 14-19.
|
| 2 |
DUBEY A, CHATTERJEE M, AHUJA N. Coreset-based neural network compression [C]// European Conference on Computer Vision. 2018: 454-470.
|
| 3 |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10)[2021-01-04].https://arxiv.org/pdf/1409.1556.pdf.
|
| 4 |
LUO J H, WU J, LIN W. ThiNet: A filter level pruning method for deep neural network compression [C]// 2017 IEEE International Conference on Computer Vision. IEEE, 2017: 5068-5076.
|
| 5 |
FU S, LI Z, LIU K, et al. Model compression for IoT applications in industry 4.0 via multi-scale knowledge transfer. IEEE Transactions on Industrial Informatics, 2020, (9): 6013- 6022.
|
| 6 |
SODHRO A H, PIRBHULAL S, ALBUQUERQUE V. Artificial intelligence-driven mechanism for edge computing-based industrial applications. IEEE Transactions on Industrial Informatics, 2019, (7): 4235- 4243.
|
| 7 |
LÜ L, BEZDEK J C, HE X L, et al. Fog-embedded deep learning for the internet of things. IEEE Transactions on Industrial Informatics, 2019, (7): 4206- 4215.
|
| 8 |
WANG T, LUO H, JIA W, et al. MTES: An intelligent trust evaluation scheme in sensor-cloud-enabled industrial internet of things. IEEE Transactions on Industrial Informatics, 2020, 16 (3): 2054- 2062.
doi: 10.1109/TII.2019.2930286
|
| 9 |
LIKAMWA R, WANG Z, CARROLL A, et al. Draining our glass: An energy and heat characterization of google glass [C]// Proceedings of 5th Asia-Pacific Workshop on Systems. 2014. DOI: 10.1145/2637166.2637230.
|
| 10 |
KANG Y, HAUSWALD J, CAO G, et al. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM SIGPLAN Notices, 2017, 52 (1): 615- 629.
|
| 11 |
ZHOU Z, CHEN X, LI E, et al. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proceedings of the IEEE, 2019, 107 (8): 1738- 1762.
doi: 10.1109/JPROC.2019.2918951
|
| 12 |
ULLRICH K, MEEDS E, WELLING M. Soft weight-sharing for neural network compression [EB/OL]. (2017–05–09) [2020–03–01]. https://arxiv.org/pdf/1702.04008.pdf.
|
| 13 |
LIN S, JI R, YAN C, et al. Towards optimal structured CNN pruning via generative adversarial learning [C]// Conference on Computer Vision and Pattern Recognition. 2019: 2790-2799.
|
| 14 |
HOSSEINI M. On the complexity reduction of dense layers from O(N2) to O(NlogN) with cyclic sparsely connected layers [D]. Baltimore County, Maryland: University of Maryland, 2019.
|
| 15 |
WANG Y, LIANG S W, LI H W , et al. A none-sparse inference accelerator that distills and reuses the computation redundancy in CNNs [C]// Proceedings of the 56th Annual Design Automation Conference. 2019. DOI: 10.1145/3316781.3317749.
|
| 16 |
IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size [EB/OL]. (2016–11–04) [2020–03–15]. https://arxiv.org/abs/1602.07360.
|
| 17 |
SOTOUDEH M, BAGHSORKHI S S. C3-Flow: Compute compression co-design flow for deep neural networks [C]// Proceedings of the 56th Annual Design Automation Conference. 2019: Article No.86.
|
| 18 |
LIN S, JI R, CHEN C, et al. Holistic CNN compression via low-rank decomposition with knowledge transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41 (12): 2889- 2905.
doi: 10.1109/TPAMI.2018.2873305
|
| 19 |
KO J H, NA T, AMIR M F, et al. Edge-Host partitioning of deep neural networks with feature space encoding for resource-constrained Internet-of-Things platforms [C]// 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance. IEEE, 2018. DOI: 10.1109/AVSS.2018.8639121.
|
| 20 |
LI P, CHEN Z, YANG L, et al, Deep convolutional computation model for feature learning on big data in internet of things [J]. IEEE Transactions on Industrial Informatics, 2018, 14(2): 790-798.
|
| 21 |
CHEN Z, GRYLLIAS K, LI W. Intelligent fault diagnosis for rotary machinery using transferable convolutional neural network. IEEE Transactions on Industrial Informatics, 2020, 16 (1): 339- 349.
doi: 10.1109/TII.2019.2917233
|
| 22 |
ZHOU J H, PANG C K, LEWIS F L, et al. Intelligent diagnosis and prognosis of tool wear using dominant feature identification. IEEE Transactions on Industrial Informatics, 2009, 5 (4): 454- 464.
doi: 10.1109/TII.2009.2023318
|
| 23 |
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network [EB/OL]. (2015-03-09) [2020-01-10]. https://arxiv.org/abs/1503.02531.
|
| 24 |
ZHANG Y, HONG G S, YE D, et al. Powder-bed fusion process monitoring by machine vision with hybrid convolutional neural networks. IEEE Transactions on Industrial Informatics, 2020, 16 (9): 5769- 5779.
doi: 10.1109/TII.2019.2956078
|
 )
)
 中文核心期刊
中文核心期刊