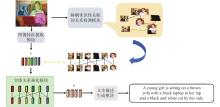
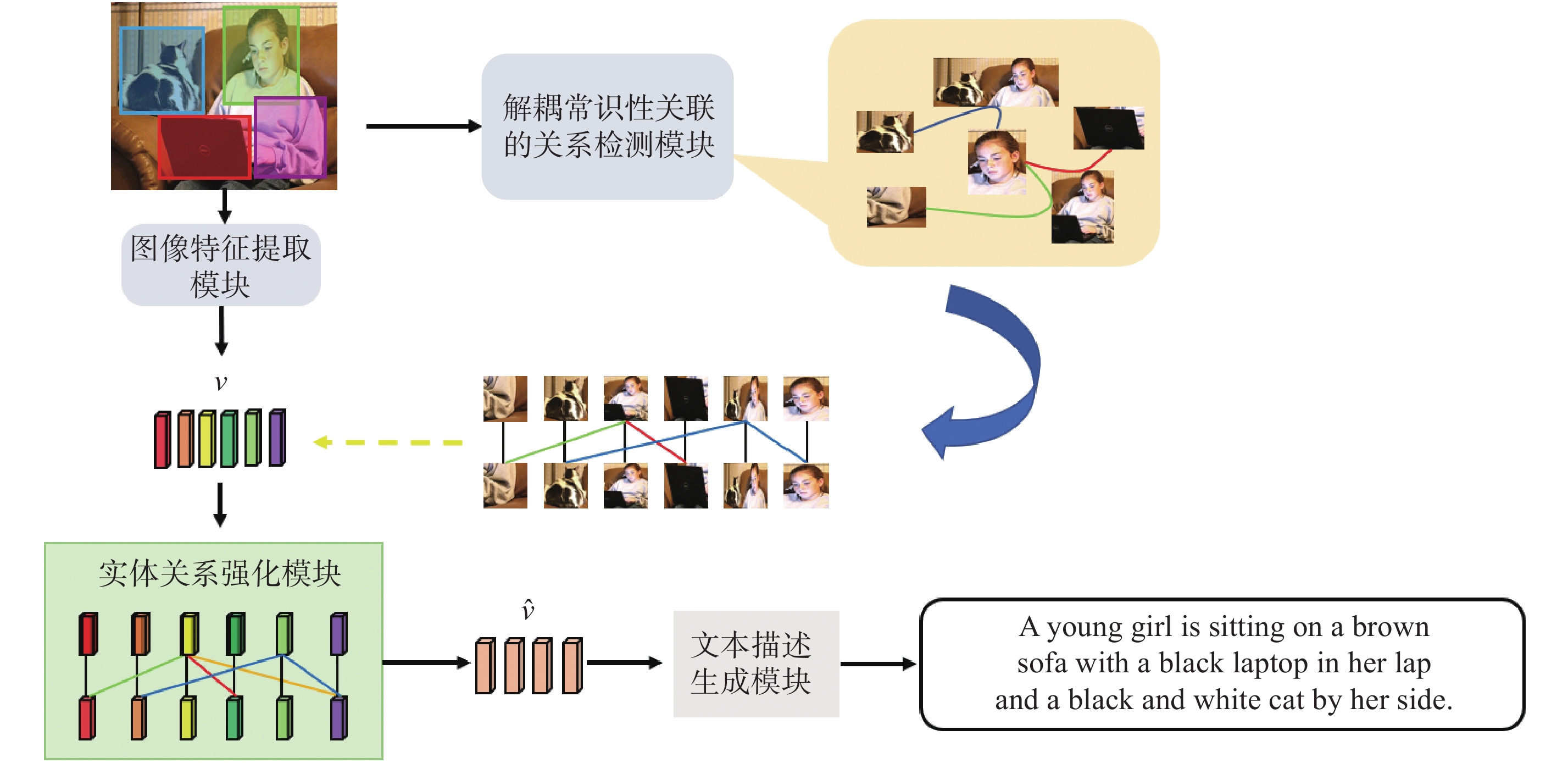
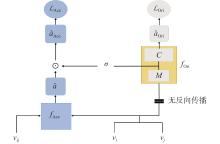
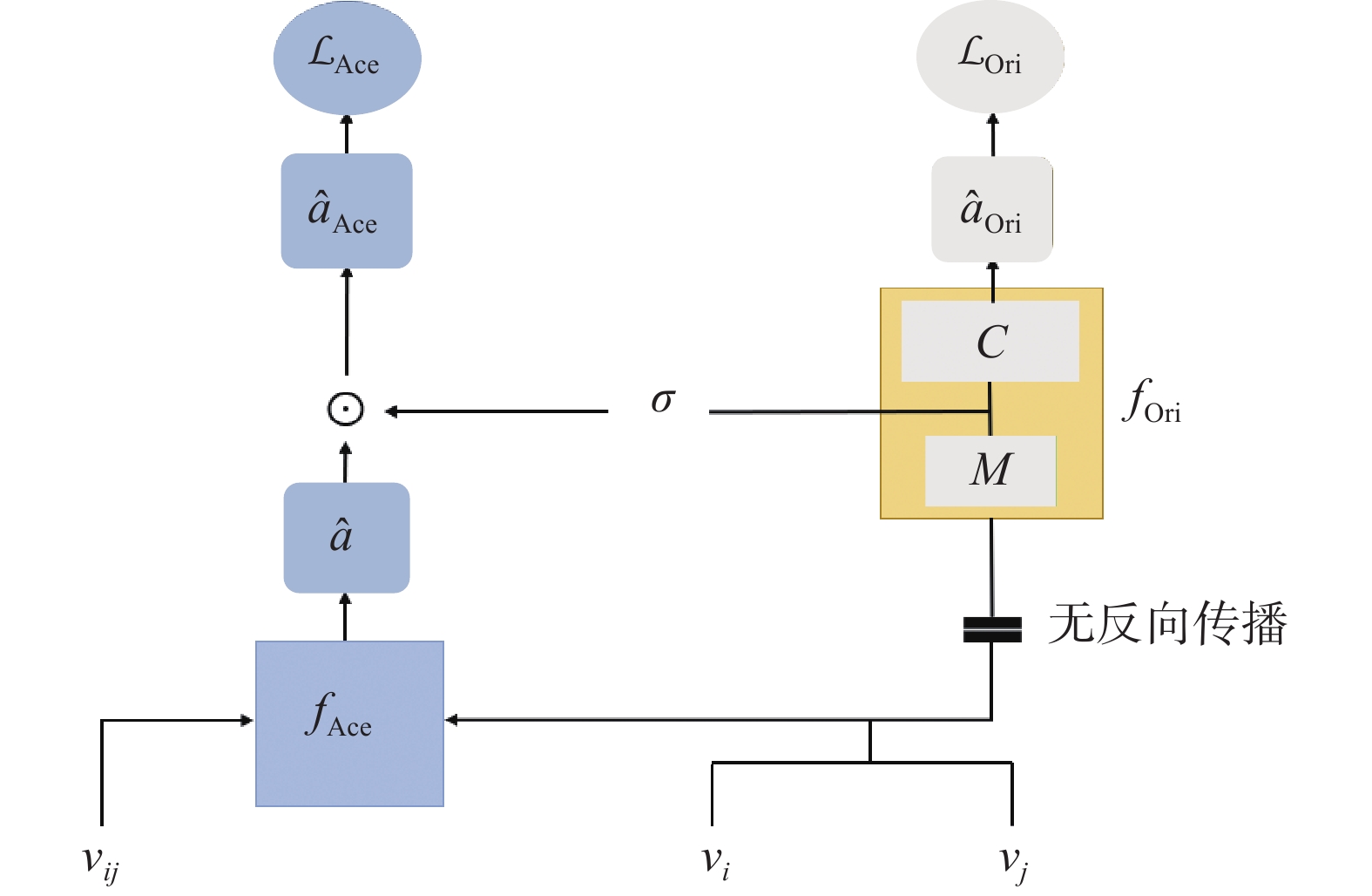
| 1 |
STEFANINI M, CORNIA M, BARALDI L, et al.. From show to tell: A survey on deep learning-based image captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (1): 539- 559.
|
| 2 |
SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2. 2014: 3104-3112.
|
| 3 |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: A neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3156-3164.
|
| 4 |
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6077-6086.
|
| 5 |
LI G, ZHU L, LIU P, et al. Entangled transformer for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8928-8937.
|
| 6 |
HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: Transforming objects into words [J]. Advances in Neural Information Processing Systems, 2019: 14733-14745.
|
| 7 |
XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention [C]// International Conference on Machine Learning. 2015: 2048-2057.
|
| 8 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
|
| 9 |
HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 4634-4643.
|
| 10 |
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10578-10587.
|
| 11 |
PAN Y W, YAO T, LI Y H, et al. X-Linear attention networks for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10971-10980.
|
| 12 |
ZHANG X, SUN X, LUO Y, et al. RSTNet: Captioning with adaptive attention on visual and non-visual words [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15465-15474.
|
| 13 |
ZENG P P, ZHANG H N, SONG J K, et al. ${\cal{S}}^2 $ transformer for image captioning [C]// Proceedings of the International Joint Conferences on Artificial Intelligence. 2022: 12675-12684.
|
| 14 |
YANG X, TANG K, ZHANG H, et al. Autoencoding scene graphs for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 10685-10694.
|
| 15 |
LUO Y, JI J, SUN X, et al. Dual-level collaborative transformer for image captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2021: 2286-2293.
|
| 16 |
LU J, XIONG C, PARIKH D, et al. Knowing when to look: Adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 375-383.
|
| 17 |
HU R H, SINGH A, DARRELL T, et al. Iterative answer prediction with pointer augmented multimodal transformers for textVQA [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9992-10002.
|
| 18 |
GAO J, MENG X, WANG S, et al. Masked non-autoregressive image captioning [EB/OL]. (2019-06-03)[2023-01-03]. https://arxiv.org/abs/1906.00717.pdf.
|
| 19 |
FEI Z. Iterative back modification for faster image captioning [C]// Proceedings of the 28th ACM International Conference on Multimedia. 2020: 3182-3190.
|
| 20 |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 7008-7024.
|
| 21 |
FENG Y, MA L, LIU W, et al. Unsupervised image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 4125-4134.
|
| 22 |
GU J, JOTY S, CAI J, et al. Unpaired image captioning via scene graph alignments [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 10323-10332.
|
| 23 |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. 2021: 8748-8763.
|
| 24 |
JOHNSON J, KARPATHY A, LI F F. DenseCap: Fully convolutional localization networks for dense captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4565-4574.
|
| 25 |
YANG L, TANG K, YANG J, et al. Dense captioning with joint inference and visual context [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2193-2202.
|
| 26 |
LI X, JIANG S, HAN J. Learning object context for dense captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2019: 8650-8657.
|
| 27 |
CORNIA M, BARALDI L, CUCCHIARA R. Show, control and tell: A framework for generating controllable and grounded captions [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8307-8316.
|
| 28 |
ZHENG Y, LI Y, WANG S. Intention oriented image captions with guiding objects [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8395-8404.
|
| 29 |
CHEN S, JIN Q, WANG P, et al. Say as you wish: Fine-grained control of image caption generation with abstract scene graphs [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9962-9971.
|
| 30 |
CHEN L, JIANG Z, XIAO J, et al. Human-like controllable image captioning with verb-specific semantic roles [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 16846-16856.
|
| 31 |
LI X R, XU C X, WANG X X, et al.. COCO-CN for cross-lingual image tagging, captioning, and retrieval. IEEE Transactions on Multimedia, 2019, 21 (9): 2347- 2360.
|
| 32 |
LAN W, LI X, DONG J. Fluency-guided cross-lingual image captioning [C]// Proceedings of the 25th ACM International Conference on Multimedia. 2017: 1549-1557.
|
| 33 |
SONG Y, CHEN S, ZHAO Y, et al. Unpaired cross-lingual image caption generation with self-supervised rewards [C]// Proceedings of the 27th ACM International Conference on Multimedia. 2019: 784-792.
|
| 34 |
GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision. 2015: 1440-1448.
|
| 35 |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context [C]// Computer Vision-ECCV 2014. 2014: 740-755.
|
| 36 |
KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3128-3137.
|
| 37 |
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002: 311-318.
|
| 38 |
BANERJEE S, LAVIE A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments [C]// Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005: 65-72.
|
| 39 |
LIN C Y. ROUGE: A package for automatic evaluation of summaries [C]// Proceedings of the Workshop on Text Summarization Branches Out. 2004: 74-81.
|
| 40 |
VEDANTAM R, LAWRENCE C, PARIKH D. CIDEr: Consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 4566-4575.
|
| 41 |
ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: Semantic propositional image caption evaluation [C]// Computer Vision-ECCV 2016. 2016: 382-398.
|
 )
)
 中文核心期刊
中文核心期刊