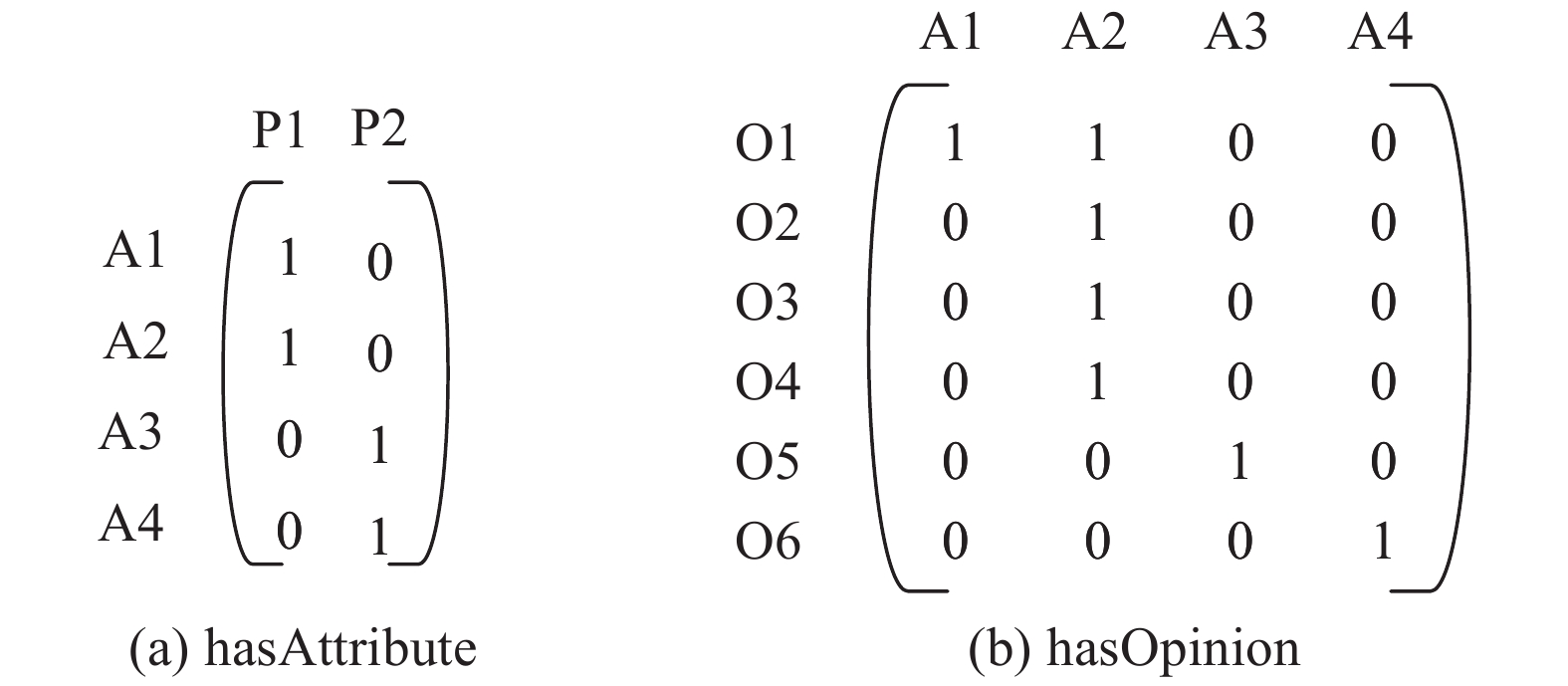
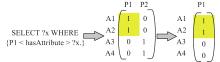
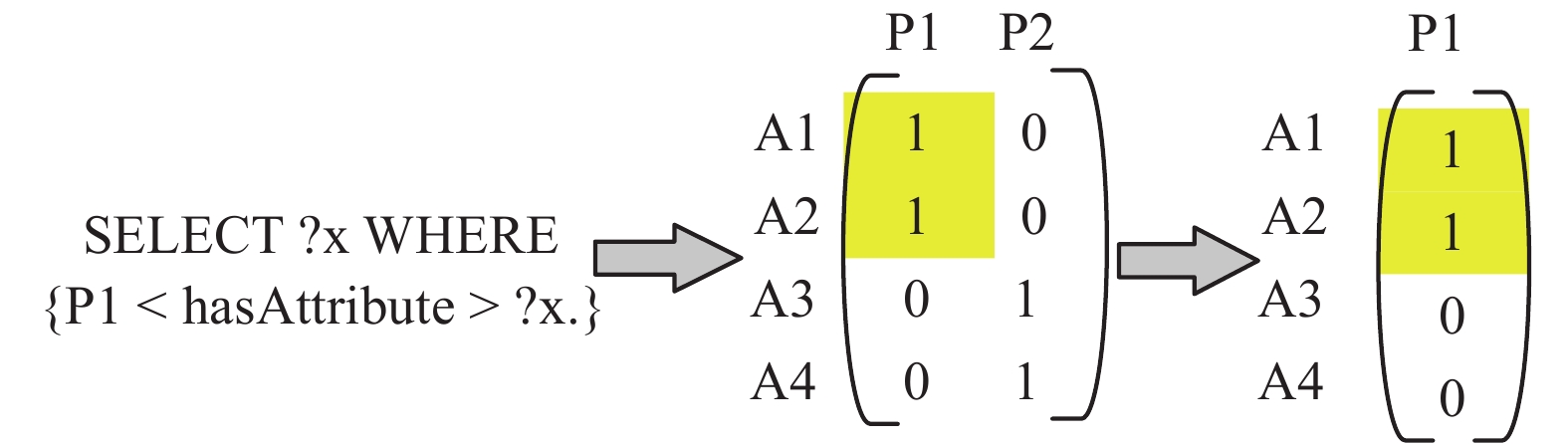
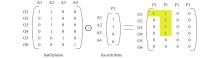
| 1 |
陈强, 代仕娅. 基于金融知识图谱的会计欺诈风险识别. 大数据, 2021, 7 (3): 116- 129.
|
| 2 |
TAKEDA A, ITO Y. A review of FinTech research. International Journal of Technology Management, 2021, 86 (1): 67- 88.
doi: 10.1504/IJTM.2021.115761
|
| 3 |
LEE K, LIU L. Scaling queries over big RDF graphs with semantic hash partitioning. Proceedings of the VLDB Endowment, 2013, 6 (14): 1894- 1905.
doi: 10.14778/2556549.2556571
|
| 4 |
NEUMANN T, WEIKUM G. The RDF-3X engine for scalable management of RDF data. The VLDB Journal, 2010, 19 (1): 91- 113.
doi: 10.1007/s00778-009-0165-y
|
| 5 |
ZOU L, ÖZSU M T, CHEN L, et al. gStore: A graph-based SPARQL query engine. The VLDB Journal, 2014, 23 (4): 565- 590.
doi: 10.1007/s00778-013-0337-7
|
| 6 |
INGALALLI V, IENCO D, PONCELET P, et al. Querying RDF data using a multigraph-based approach [C]// International Conference on Extending Database Technology (EDBT 2016). 2016: 245-256.
|
| 7 |
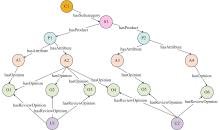
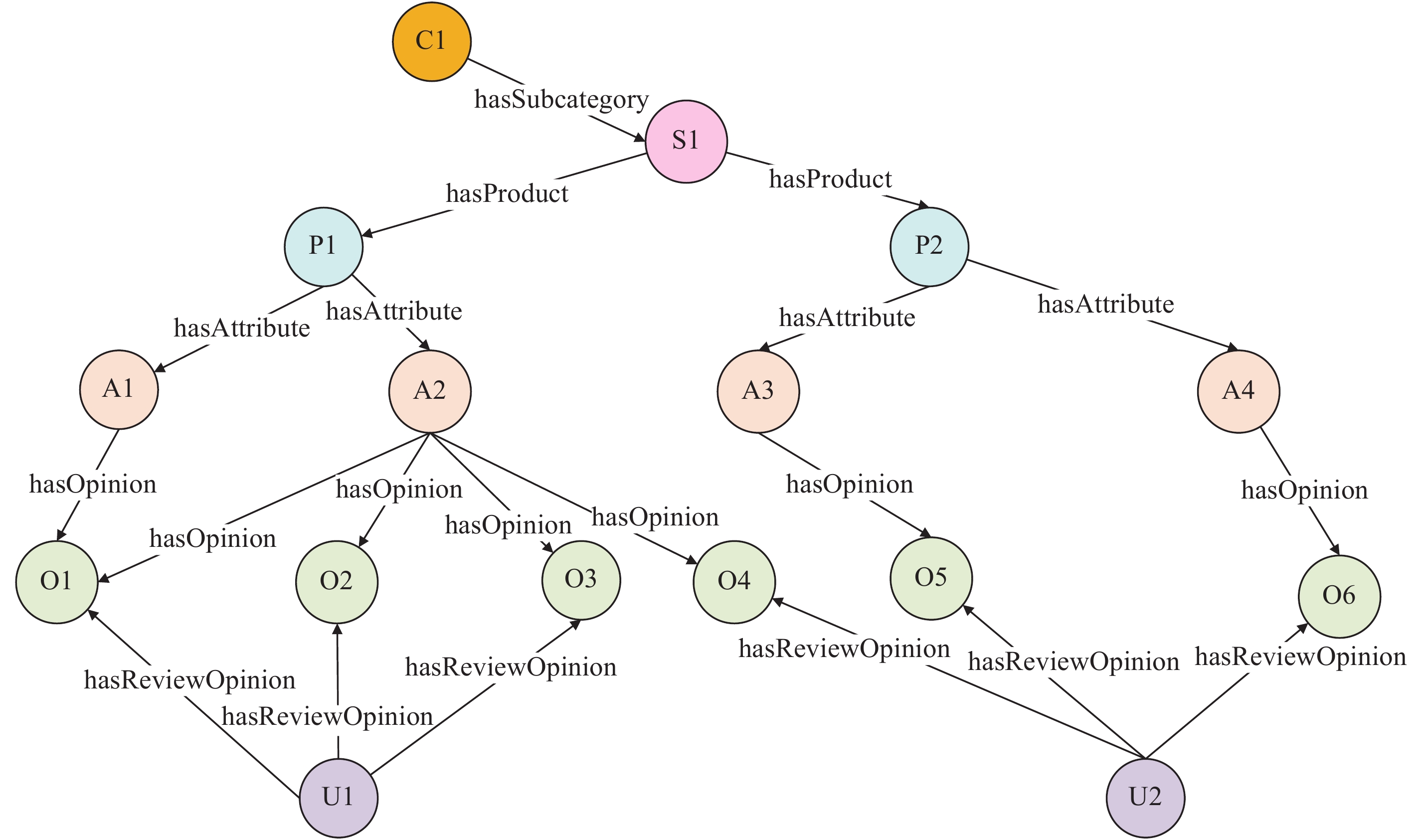
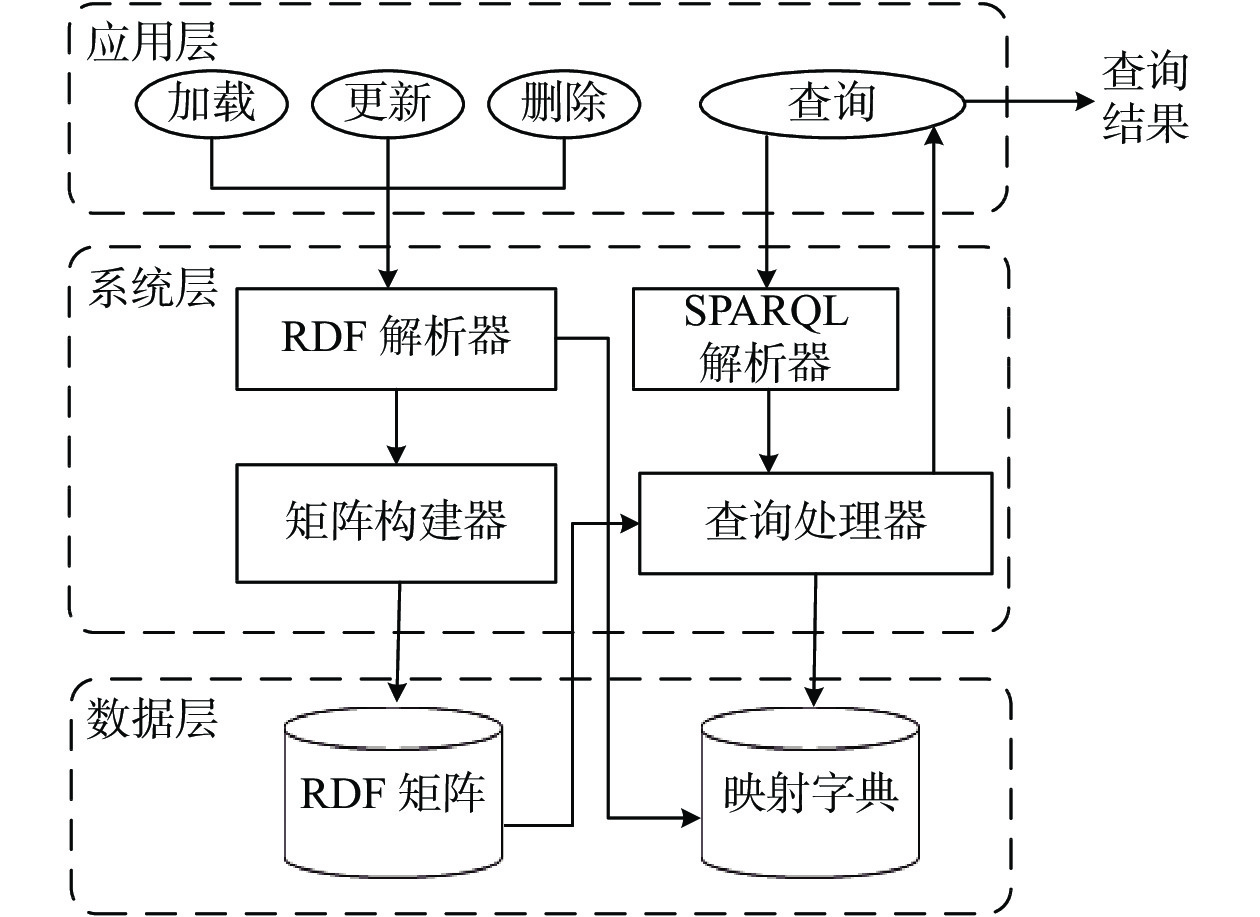
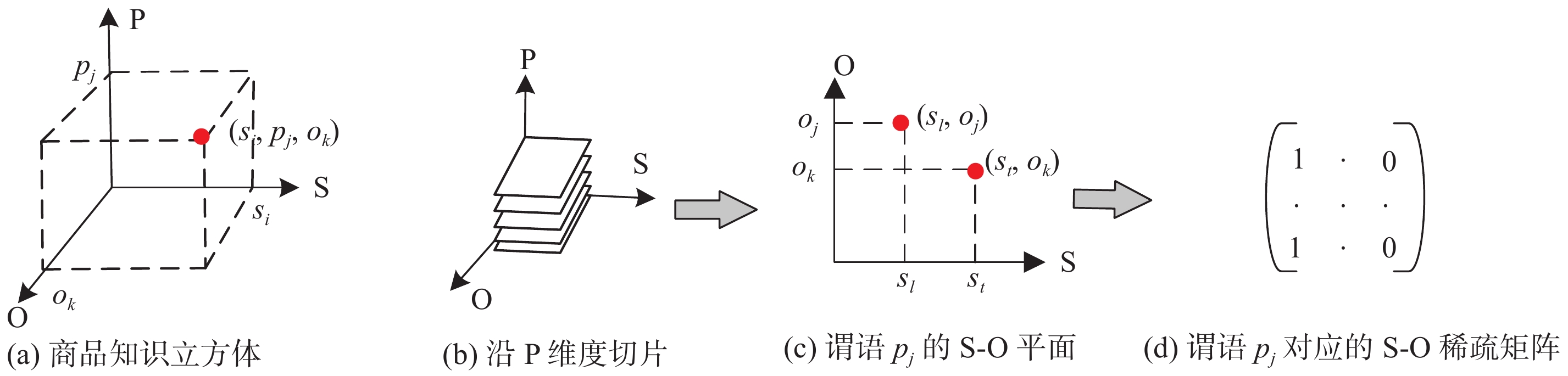
黄涛贻, 李优, 宋浩, 等. 大规模商品知识的组织和查询优化. 计算机工程与应用, 2020, 56 (21): 154- 163.
|
| 8 |
SCHTZLE A, PRZYJACIEL-ZABLOCKI M, SKILEVIC S, et al. S2RDF: RDF querying with SPARQL on Spark. Proceedings of the VLDB Endowment, 2016, 9 (10): 804- 815.
doi: 10.14778/2977797.2977806
|
| 9 |
ATRE M, CHAOJI V, ZAKI M J, et al. Matrix Bit loaded: A scalable lightweight join query processor for RDF data [C]// Proceedings of the 19th International Conference on World Wide Web (WWW 2010). 2010: 41-50.
|
| 10 |
KIM J, SHIN H, HAN W S, et al. Taming subgraph isomorphism for RDF query processing. Proceedings of the VLDB Endowment, 2015, 8 (11): 1238- 1249.
doi: 10.14778/2809974.2809985
|
| 11 |
ZOUAGHI I, MESMOUDI A, GALICIA J, et al. Query optimization for large scale clustered RDF data [C]// Proceedings of the 22nd International Workshop on Design, Optimization, Languages and Analytical Processing of Big Data. 2020: 56-65.
|
| 12 |
MANOLESCU I. Exploring RDF graphs through summarization and analytic query discovery [C]// Proceedings of the 22nd International Workshop On Design, Optimization, Languages and Analytical Processing of Big Data. 2020: 1-5.
|
| 13 |
SONG J, PENG P, FENG Z, et al. MapSQ: A plugin-based MapReduce framework for SPARQL queries on GPU [C]// WWW’18 Companion. 2018: 81-82.
|
| 14 |
TRAN H N, CAMBRIA E, DO H G. Efficient semantic search over structured web data: A GPU approach [C]// International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2017). 2017: 549-562.
|
| 15 |
CHANTRAPORNCHAI C, CHOKSUCHAT C. TripleID-Q: RDF query processing framework using GPU. IEEE Transactions on Parallel and Distributed Systems, 2018, 29 (9): 2121- 2135.
doi: 10.1109/TPDS.2018.2814567
|
| 16 |
ZHANG X, ZHANG M, PENG P, et al. A scalable sparse matrix-based join for SPARQL query processing [C]// International Conference on Database Systems for Advanced Applications (DASFAA 2019). 2019: 510-514.
|
| 17 |
WANG S, LOU C, CHEN R, et al. Fast and concurrent RDF queries using RDMA-assisted GPU graph exploration [C]// Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC’18). 2018: 651-664.
|
| 18 |
JAMOUR F, ABDELAZIZ I, CHEN Y, et al. Matrix algebra framework for portable, scalable and efficient query engines for RDF graphs [C]// Proceedings of the Fourteenth EuroSys Conference. 2019: 1-15.
|
 ), 宋浩, 林煜明*(
), 宋浩, 林煜明*( 中国综合性科技类核心期刊(北大核心)
中国综合性科技类核心期刊(北大核心)