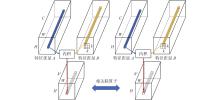
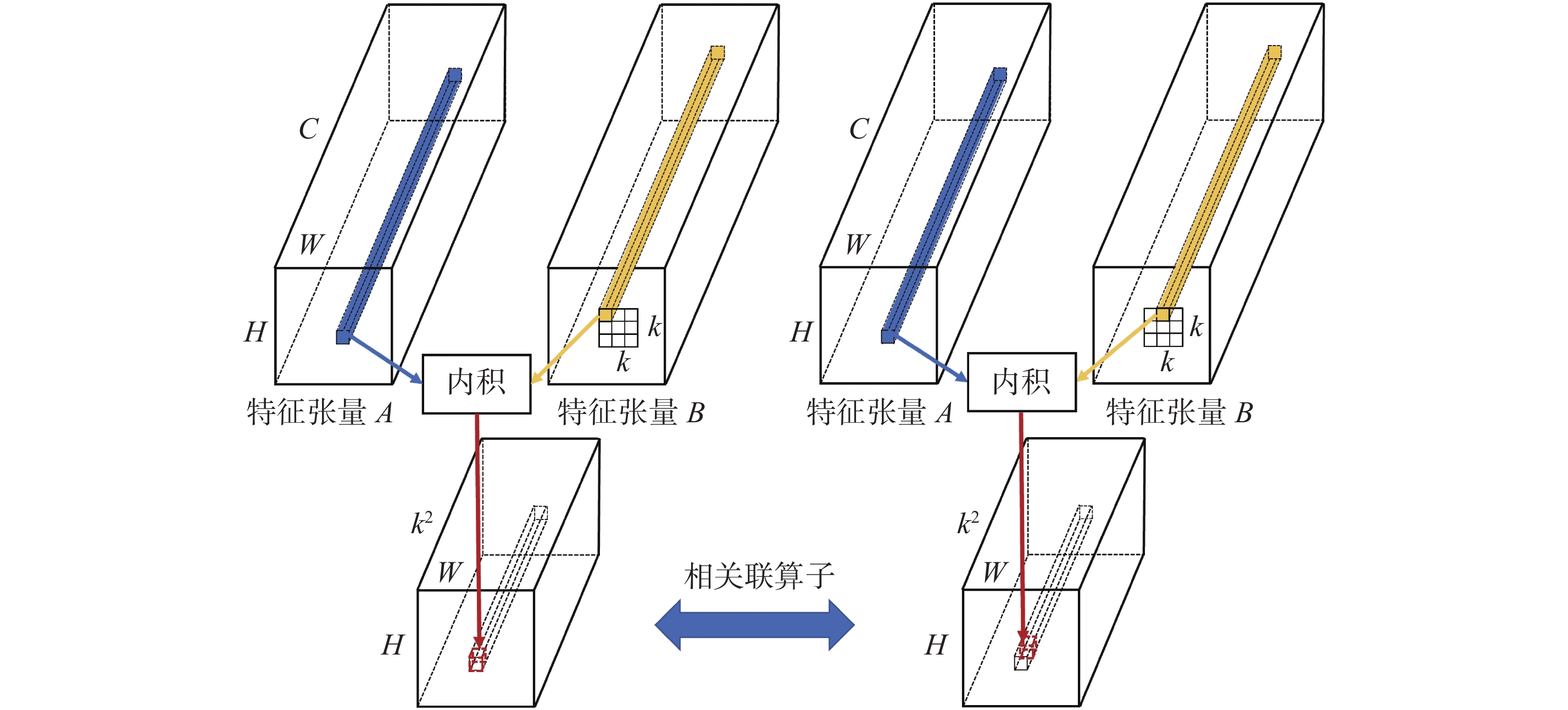
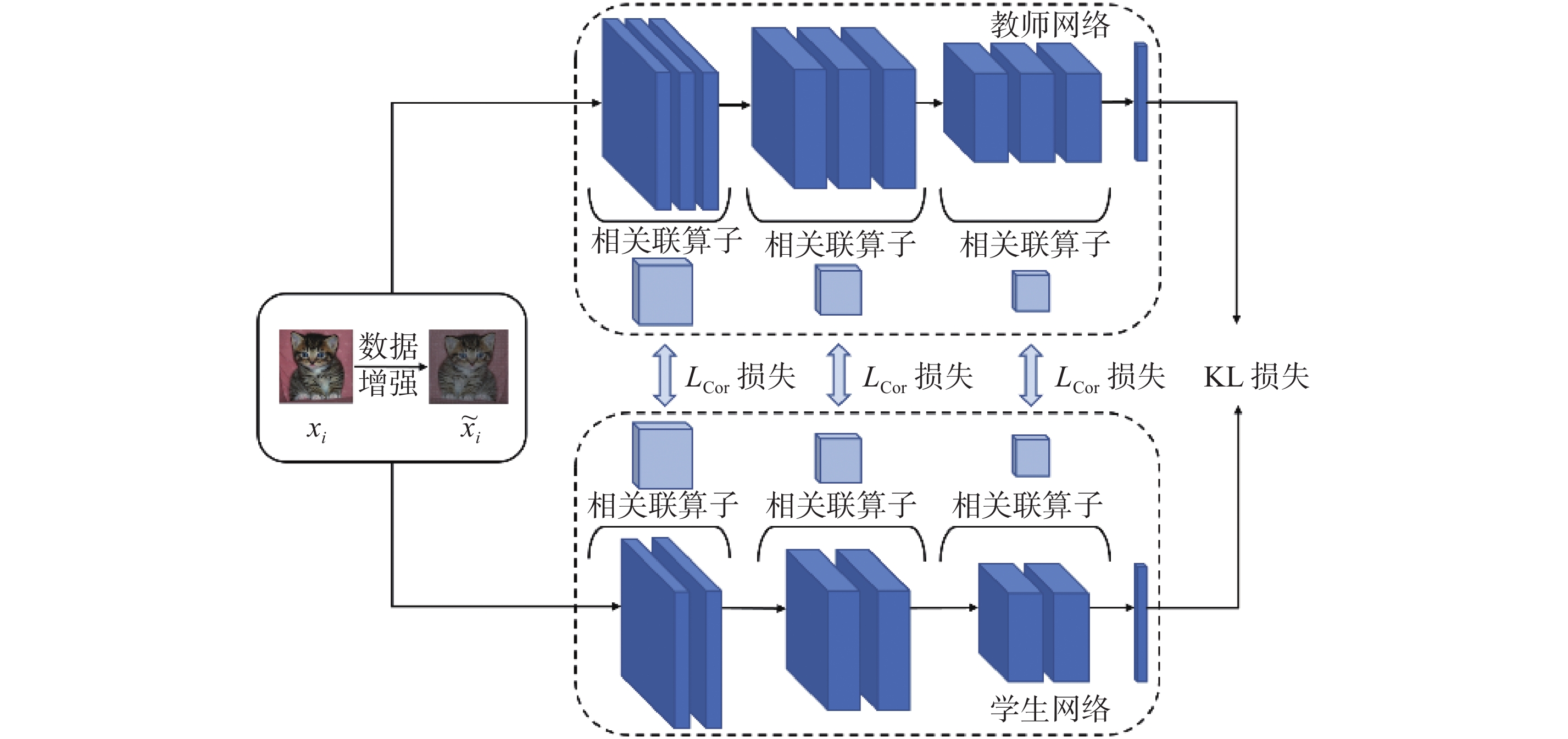
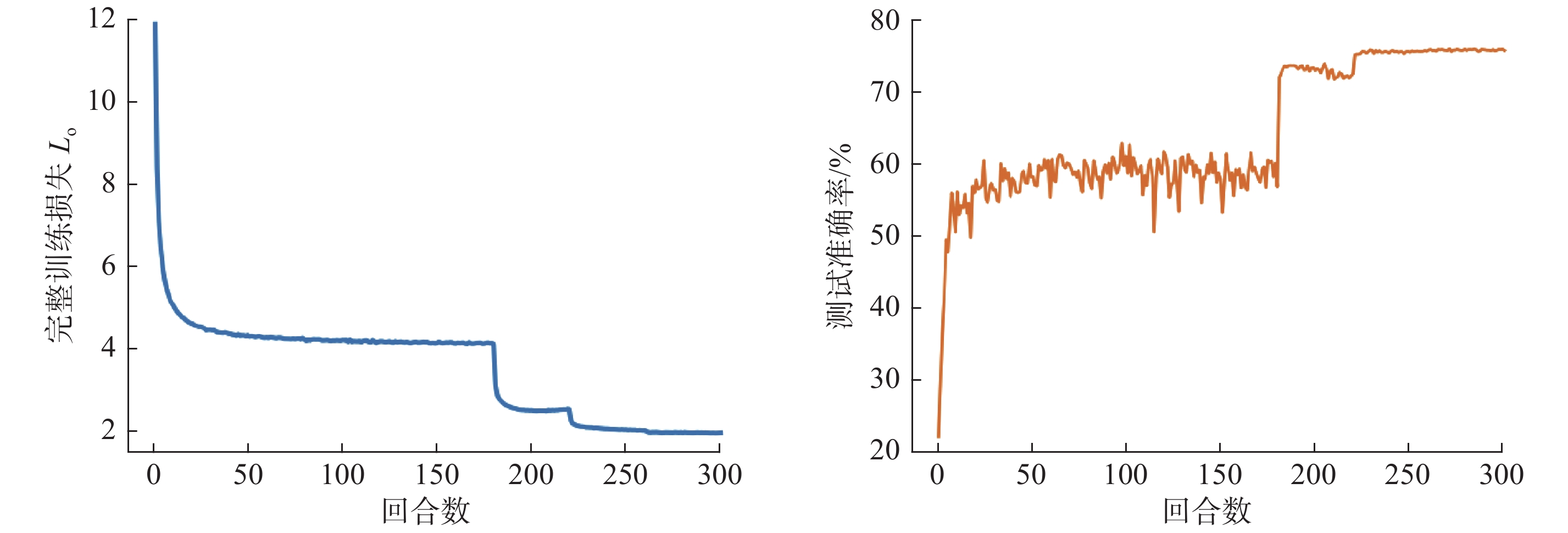
| 1 |
袁勇, 周涛, 周傲英, 等. 区块链技术: 从数据智能到知识自动化. 自动化学报, 2017, 43 (9): 1485- 1490.
|
| 2 |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the Advances in Neural Information Processing Systems. 2012: 1097-1105.
|
| 3 |
RENS Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
|
| 4 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
|
| 5 |
纪荣嵘, 林绍辉, 晁飞, 等. 深度神经网络压缩与加速综述. 计算机研究与发展, 2018, 55 (9): 1871- 1888.
|
| 6 |
孟宪法, 刘方, 李广, 等. 卷积神经网络压缩中的知识蒸馏技术综述. 计算机科学与探索, 2021, 15 (10): 1812- 1818.
|
| 7 |
DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: Learning optical flow with convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision. 2015: 2758-2766.
|
| 8 |
ILG E, MAYER N, SAIKIA T, et al. FlowNet 2.0: Evolution of optical flow estimation with deep networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2462-2470.
|
| 9 |
WANG H, TRAN D, TORRESANI L, et al. Video modeling with correlation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020: 352-361.
|
| 10 |
LI H, KADAV A, DURDANOVIC I, et al. Pruning filters for efficient convnets [EB/OL]. (2017-03-10)[2022-06-11]. https://arxiv.org/pdf/1608.08710.pdf.
|
| 11 |
LIN J, RAO Y M, LU J W, et al. Runtime neural pruning [C]// Proceedings of Advances in Neural Information Processing Systems. 2017: 2178–2188.
|
| 12 |
HUBARA I, COURBARIAUS M, SOUDRY D, et al. Binarized neural networks: Training deep neural networks with weights and activations constrained to + 1 or –1 [EB/OL]. (2016-03-17)[2022-06-01]. https://arxiv.org/pdf/1602.02830.pdf.
|
| 13 |
JACOB B, KLIGYS S, CHEN B, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2704-2713.
|
| 14 |
章振宇, 谭国平, 周思源. 基于1-bit压缩感知的高效无线联邦学习算法. 计算机应用, 2022, 42 (6): 1675- 1682.
|
| 15 |
TAI C, XIAO T, ZHANG Y, et al. Convolutional neural networks with low-rank regularization [EB/OL]. (2016-02-14)[2022-06-15]. https://arxiv.org/pdf/1511.06067.pdf.
|
| 16 |
IOANOU Y, ROBERTSON D, SHOTTON J, et al. Training CNNs with low-rank filters for efficient image classification [C]//Proceedings of the International Conference on Learning Representation. 2016: 45-61.
|
| 17 |
HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017-04-17)[2022-06-01]. https://arxiv.org/pdf/1704.04861.pdf.
|
| 18 |
TAN M, LE Q. EfficientNet: Rethinking model scaling for convolutional neural networks [C]// Proceedings of the International Conference on Machine Learning. 2019: 6105–6114.
|
| 19 |
HINTON G E, VINYALS O, DEAN J. Distilling the knowledge in a neural network [C]// Proceedings of the International Conference on Learning Representation Workshop. 2015: 60-72.
|
| 20 |
ROMERO A, BALLAS N, KAHOU S E, et al. FitNets: Hints for thin deep nets [C]// Proceedings of the International Conference on Learning Representation. 2015: 73-85.
|
| 21 |
ZAGORUYKO S, KOMODAKIS N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer [EB/OL]. (2017-02-12)[2022-06-14]. https://arxiv.org/pdf/1612.03928.pdf.
|
| 22 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth $16 \times 16 $ words: Transformers for image recognition at scale [EB/OL]. (2021-06-03)[2022-06-13]. https://arxiv.org/pdf/2010.11929v2.pdf.
|
| 23 |
WANG W H, WEI F R, DONG L, et al. MINILM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers [C]// Proceedings of the Advances in Neural Information Processing Systems. 2020: 5776-5788.
|
| 24 |
AGUILAR G, LING Y, ZHANG Y, et al. Knowledge distillation from internal representations [C]// Proceedings of the Association for the Advancement of Artificial Intelligence. 2020: 7350-7357.
|
| 25 |
YIM J, JOO D, BAE J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 7130–7138.
|
| 26 |
PARK W, KIM D, LU Y, et al. Relational knowledge distillation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 3967-3976.
|
| 27 |
LIU Y F, CAO J J, LI B, et al. Knowledge distillation via instance relationship graph [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 7096-7104.
|
| 28 |
TUNG F, MORI G. Similarity-preserving knowledge distillation [C]// Proceedings of the IEEE International Conference on Computer Vision. 2019: 1365-1374.
|
| 29 |
KIM J, PARK S, KWAK N. Paraphrasing complex network: Network compression via factor transfer [C]// Proceedings of the Advances in Neural Information Processing System. 2018: 2760–2769.
|
| 30 |
HEO B, LEE M, YUN S, et al. Knowledge transfer via distillation of activation boundaries formed by hidden neurons [C]// Proceedings of the Association for the Advancement of Artificial Intelligence. 2019: 3779-3787.
|
| 31 |
SRINIVAS S, FLEURET F. Knowledge transfer with jacobian matching [C]// Proceedings of the 35th International Conference on Machine Learning. 2018: 4723-4731.
|
| 32 |
TIAN Y L, KRISHNAN D, ISOLA P. Contrastive representation distillation [EB/OL]. (2019-10-23)[2022-06-06]. https://arxiv.org/pdf/1910.10699v1.pdf.
|
| 33 |
XU G D, LIU Z W, LI X X, et al. Knowledge distillation meets self-supervision [C]// Proceedings of the European Conference on Computer Vision. 2020: 588-604.
|
| 34 |
SU C, LI P, XIE Y, et al. Hierarchical knowledge squeezed adversarial network compression [C]// Proceedings of the Association for the Advancement of Artificial Intelligence. 2020: 11370-11377.
|
| 35 |
SHEN Z Q, HE Z K, XUE X Y. MEAL: Multi-model ensemble via adversarial learning [C]// Proceedings of the Association for the Advancement of Artificial Intelligence. 2019: 4886-4893.
|
| 36 |
CHUNG I, PARK S U, KIM J, et al. Feature-map-level online adversarial knowledge distillation [C]// Proceedings of the International Conference on Machine Learning. 2020: 2006-2015.
|
| 37 |
JIN X, PENG B Y, WU Y C, et al. Knowledge distillation via route constrained optimization [C]// Proceedings of the IEEE International Conference on Computer Vision. 2019: 1345-1354.
|
| 38 |
ZAGORUYKO S, KOMODAKIS N. Wide residual networks [EB/OL]. (2017-05-23)[2022-06-01]. https://arxiv.org/pdf/1605.07146.pdf.
|
 )
)
 中文核心期刊
中文核心期刊