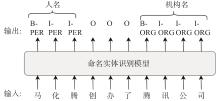
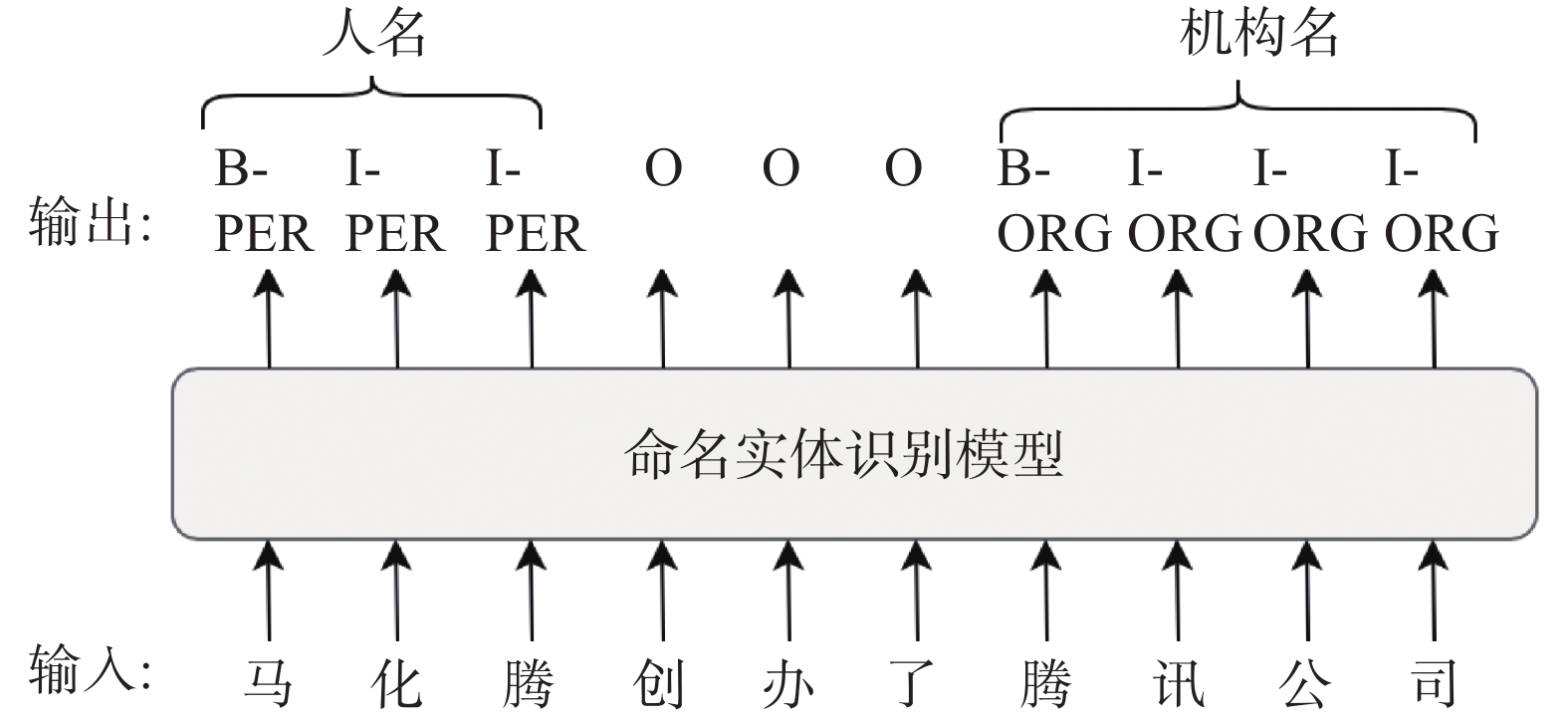
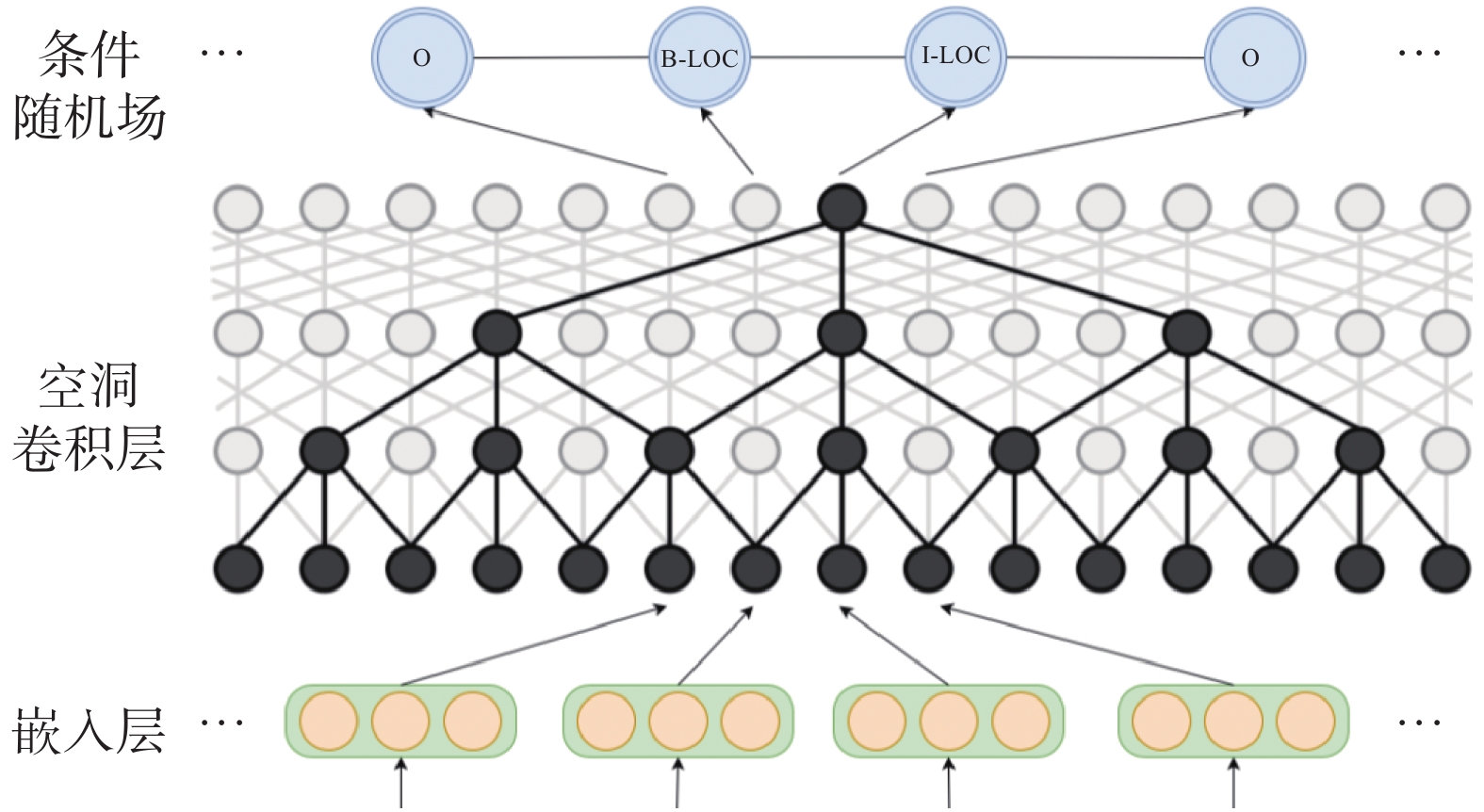
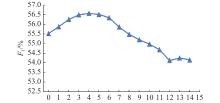
| 1 |
PARK D S, CHAN W, ZHANG Y, et al. Specaugment: A simple data augmentationmethod for automatic speech recognition [EB/OL]. (2019-12-03)[2021-08-24]. https://arxiv.org/abs/1904.08779.
|
| 2 |
WEI J W, ZOU K. Eda: Easy data augmentation techniques for boosting perfor-mance on text classification tasks [EB/OL]. (2019-08-25)[2021-08-24]. https://arxiv.org/pdf/1901.11196.pdf.
|
| 3 |
WEISCHEDEL R. BEN: Description of the PLUM system as used for MUC-6 [C]// Proceedings of the 6th Conference on Message Understanding. 1995: 55-69.
|
| 4 |
ABERDEEN J, BURGER J, CONNOLLY D, et al. MITRE-Bedford: Description of the ALEMBIC system as used for MUC-4 [C]// Proceedings of the 4th Conference on Message Understanding. 1992: 215-222.
|
| 5 |
HOBBS J R, BEAR J, ISRAEL D, et al. SRI international fastus system MUC-6 test results and analysis [C]// Proceedings of the 6th Conference on Message Understanding. 1995.
|
| 6 |
MAYFIELD J, MCNAMEE P, PIATKO C. Named entity recognition using hundreds of thousands of features [C]// Proceedings of the Seventh Conference on Natural Language Learning. 2003: 184-187.
|
| 7 |
RABINERLR, JUANGB-H. An introduction to hidden Markov models. IEEE Assp Magazine, 1986, 3 (1): 4- 16.
|
| 8 |
LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: Probabilis-tic models for segmenting and labeling sequence data [C]// Proceedings of the Eighteenth International Conference on Machine Learning. 2001: 282-289.
|
| 9 |
STRUBELL E, VERGA P, BELANGER D, et al. Fast and accurate entity recognitionwith iterated dilated convolutions [EB/OL]. (2017-07-22)[2021-08-24]. https://arxiv.org/pdf/1702.02098.pdf.
|
| 10 |
HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL]. (2015-08-09)[2021-08-24]. https://arxiv.org/pdf/1508.01991.pdf.
|
| 11 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
|
| 12 |
YAN H, DENG B, LI X, et al. TENER: Adapting transformer encoder for named entity recognition [EB/OL]. (2019-12-10)[2021-08-24]. https://arxiv.org/abs/1911.04474v2.
|
| 13 |
CHIU J P, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs. Transactions of the Association for Computational Linguistics, 2016, (4): 357- 370.
|
| 14 |
CETOLI A, BRAGAGLIA S, O’HARNEY A D, et al. Graph convolutional networks for named entity recognition [EB/OL]. (2018-02-14)[2021-08-24]. https://arxiv.org/pdf/1709.10053.pdf.
|
| 15 |
ZHANG Y, YANG J. Chinese NER using lattice LSTM [EB/OL]. (2018-07-05)[2021-08-24]. https://arxiv.org/pdf/1805.02023.pdf.
|
| 16 |
MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Preceedings of ACL. 2013: 3111-3119.
|
| 17 |
PENNINGTON J, SOCHER R, MANNING C. Glove: Global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1532-1543.
|
| 18 |
BOJANOWSKI P, GRAVE E, JOULIN A, et al. Enriching word vectors with sub- word information. Transactions of the Association for Computational Linguistics, 2017, (5): 135- 146.
|
| 19 |
PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [EB/OL]. (2018-03-22)[2021-09-01]. https://www.researchgate.net/publication/323217640_Deep_contextualized_word_representations.
|
| 20 |
AKBIK A, BLYTHE D, VOLLGRAF R. Contextual string embeddings for sequence labeling [C]// Proceedings of the 27th International Conference on Computational Linguistics. 2018: 1638-1649.
|
| 21 |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019-05-24)[2021-08-24]. https://arxiv.org/pdf/1810.04805.pdf.
|
| 22 |
RADFORD A. Language models are unsupervised multitask learners [EB/OL]. (2019-02-19)[2021-09-01]. https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf.
|
| 23 |
BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [EB/OL]. (2020-07-22)[2021-08-24]. https://arxiv.org/abs/2005.14165v2.
|
| 24 |
GUO H, MAO Y, ZHANG R. Augmenting data with mixup for sentence classification: An empirical study [EB/OL]. (2019-05-22)[2021-08-24]. https://arxiv.org/abs/1905.08941.
|
| 25 |
LUQUE F M. Atalaya at TASS 2019: Data augmentation and robust embeddings for sentiment analysis [EB/OL]. (2019-09-25)[2021-08-24]. https://arxiv.org/abs/1909.11241.
|
| 26 |
DAI X, ADEL H. An analysis of simple data augmentation for named entity recognition [EB/OL]. (2020-10-22)[2021-08-24]. https://arxiv.org/abs/2010.11683.
|
| 27 |
CHEN J, WANG Z, TIAN R, et al. Local additivity based data augmentation for semi-supervised NER [EB/OL]. (2020-10-04)[2021-08-24]. https://arxiv.org/abs/2010.01677.
|
| 28 |
KERAGHEL A, BENABDESLEM K, CANITIA B. Data augmentation process to improve deep learning-based NER task in the automotive industry field [C]//2020 International Joint Conference on Neural Networks (IJCNN). 2020: 1-8.
|
| 29 |
LOSHCHILOV I, HUTTER F. Fixing weight decay regularization in adam [EB/OL]. (2019-01-04)[2021-08-24]. https://arxiv.org/abs/1711.05101v1.
|
 ), 郭小鹤1, 薛峪峰1, 杨琳2,*(
), 郭小鹤1, 薛峪峰1, 杨琳2,*( 中文核心期刊
中文核心期刊