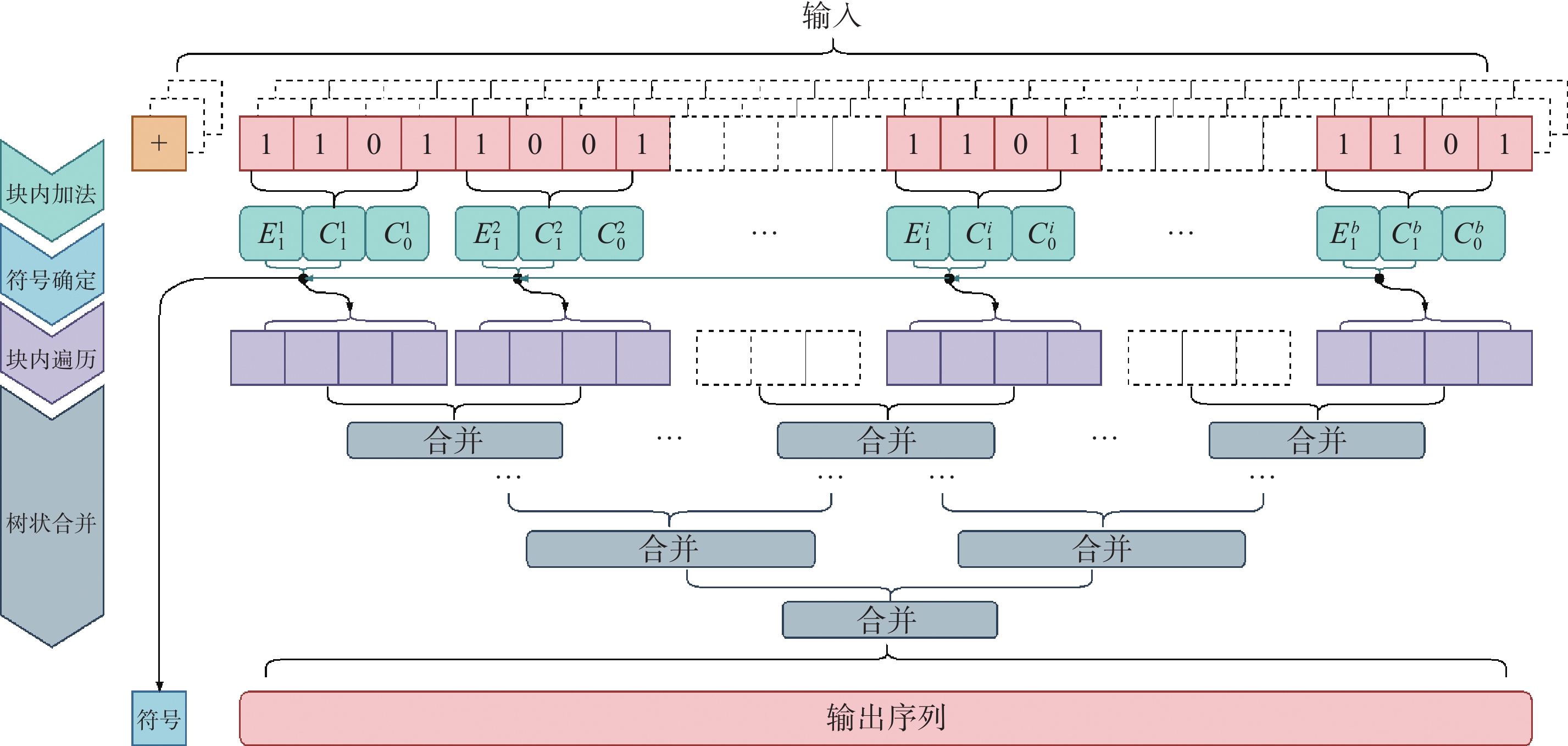
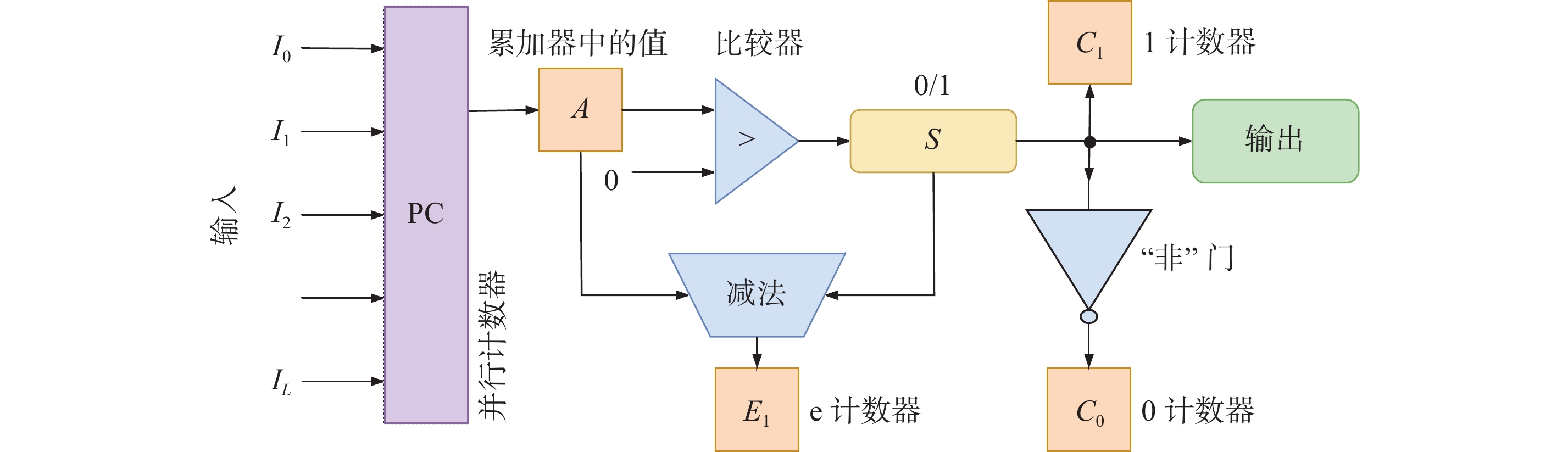
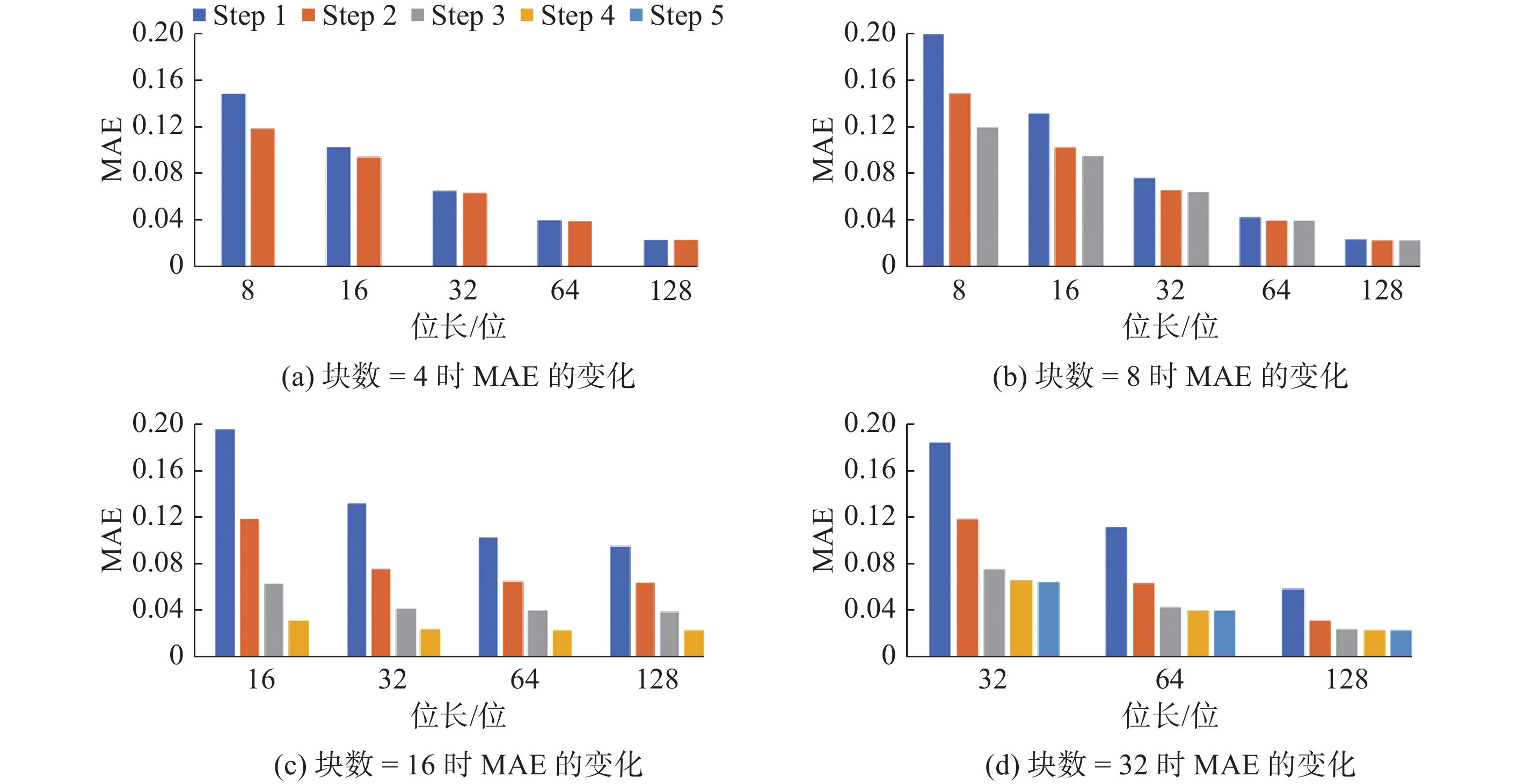
| 1 |
JIANG W W, YANG L, DASGUPTA S, et al.. Standing on the shoulders of giants: Hardware and neural architecture co-search with hot start. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39 (11): 4154- 4165.
|
| 2 |
JIANG W W, YANG L, SHA E H M, et al.. Hardware/software co-exploration of neural architectures. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39 (12): 4805- 4815.
|
| 3 |
SONG Y H, JIANG W W, LI B B, et al. Dancing along battery: Enabling transformer with run-time reconfigurability on mobile devices [C]// 2021 58th ACM/IEEE Design Automation Conference. 2021: 1003-1008.
|
| 4 |
JIANG W W, ZHANG X Y, SHA E H M, et al. Accuracy vs. efficiency: Achieving both through FPGA-implementation aware neural architecture search [C]// Proceedings of the 56th Annual Design Automation Conference. 2019. DOI: https://doi.org/10.1145/3316781.3317757.
|
| 5 |
PENG H, HUANG S, GENG T, et al. Accelerating transformer-based deep learning models on FPGAs using column balanced block pruning [C]// 2021 22nd International Symposium on Quality Electronic Design. 2021: 142-148.
|
| 6 |
QI P J, SHA E H M, ZHUGE Q F, et al. Accelerating framework of transformer by hardware design and model compression co-optimization [C]// 2021 IEEE/ACM International Conference on Computer Aided Design. 2021. DOI: https://doi.org/10.1109/ICCAD51958.2021.9643586.
|
| 7 |
YANG L, JIANG W W, LIU W, et al. Co-exploring neural architecture and network-on-chip design for real-time artificial intelligence [C]// 2020 25th Asia and South Pacific Design Automation Conference. 2020: 85-90.
|
| 8 |
GAINES B R. Stochastic Computing Systems [M]// TOU J T. Advances in Information Systems Science. New York: Springer, 1969: 37-172.
|
| 9 |
LI B, NAJAFI M H, LILJA D J. Using stochastic computing to reduce the hardware requirements for a restricted boltzmann machine classifier [C]// Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. 2016: 36-41.
|
| 10 |
LI B, NAJAFI M H, YUAN B, et al. Quantized neural networks with new stochastic multipliers [C]// 2018 19th International Symposium on Quality Electronic Design. 2018: 376-382.
|
| 11 |
LI B, QIN Y, YUAN B, et al. Neural network classifiers using stochastic computing with a hardware-oriented approximate activation function [C]// 2017 IEEE International Conference on Computer Design. 2017: 97-104.
|
| 12 |
LI B, QIN Y, YUAN B, et al.. Neural network classifiers using a hardware-based approximate activation function with a hybrid stochastic multiplier. ACM Journal on Emerging Technologies in Computing Systems, 2019, 15 (1): 12.
|
| 13 |
LIU Y, LIU S, WANG Y, et al.. A survey of stochastic computing neural networks for machine learning applications. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32 (7): 2809- 2824.
|
| 14 |
QIAN W, LI X, RIEDEL M D, et al.. An architecture for fault-tolerant computation with stochastic logic. IEEE Transactions on Computers, 2011, 60 (1): 93- 105.
|
| 15 |
KIM K, KIM J, YU J, et al. Dynamic energy-accuracy trade-off using stochastic computing in deep neural networks [C]// Proceedings of the 53rd Annual Design Automation Conference. 2016. DOI: https://doi.org/10.1145/2897937.2898011.
|
| 16 |
ZHAKATAYEV A, LEE S, SIM H, et al. Sign-magnitude SC: Getting 10X accuracy for free in stochastic computing for deep neural networks [C]// 2018 55th ACM/ESDA/IEEE Design Automation Conference. 2018: 158.
|
| 17 |
JENSON D, RIEDEL M. A deterministic approach to stochastic computation [C]// 2016 IEEE/ACM International Conference on Computer-Aided Design. 2016. DOI: https://doi.org/10.1145/2966986.2966988.
|
| 18 |
SIM H, LEE J. A new stochastic computing multiplier with application to deep convolutional neural networks [C]// Proceedings of the 54th Annual Design Automation Conference. 2017. DOI: https://doi.org/10.1145/3061639.3062290.
|
| 19 |
FARAJI S R, NAJAFI M H, LI B, et al. Energy-efficient convolutional neural networks with deterministic bit-stream processing [C]// 2019 Design, Automation & Test in Europe Conference & Exhibition. 2019: 1757-1762.
|
| 20 |
WU D, LI J, YIN R, et al. uGEMM: Unary computing architecture for GEMM applications [C]// Proceedings-International Symposium on Computer Architecture. 2020: 377-390.
|
| 21 |
SONG Y H, SHA E H M, ZHUGE Q F, et al. BSC: Block-based stochastic computing to enable accurate and efficient TinyML [C]// 2022 27th Asia and South Pacific Design Automation Conference. 2022: 314-319.
|
 ), Yuhong SONG
), Yuhong SONG
 中国综合性科技类核心期刊(北大核心)
中国综合性科技类核心期刊(北大核心)