 中文核心期刊
中文核心期刊Journal of East China Normal University(Natural Science) ›› 2024, Vol. 2024 ›› Issue (2): 131-142.doi: 10.3969/j.issn.1000-5641.2024.02.014
• Computer Science • Previous Articles Next Articles
Jiawei LIU, Xin LIN*( )
)
Received:2023-03-08
Online:2024-03-25
Published:2024-03-18
Contact:
Xin LIN
E-mail:xlin@cs.ecnu.edu.cn
CLC Number:
Jiawei LIU, Xin LIN. An image caption generation algorithm based on decoupling commonsense association[J]. Journal of East China Normal University(Natural Science), 2024, 2024(2): 131-142.
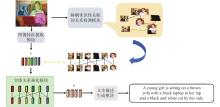
Fig.1
Model structure"
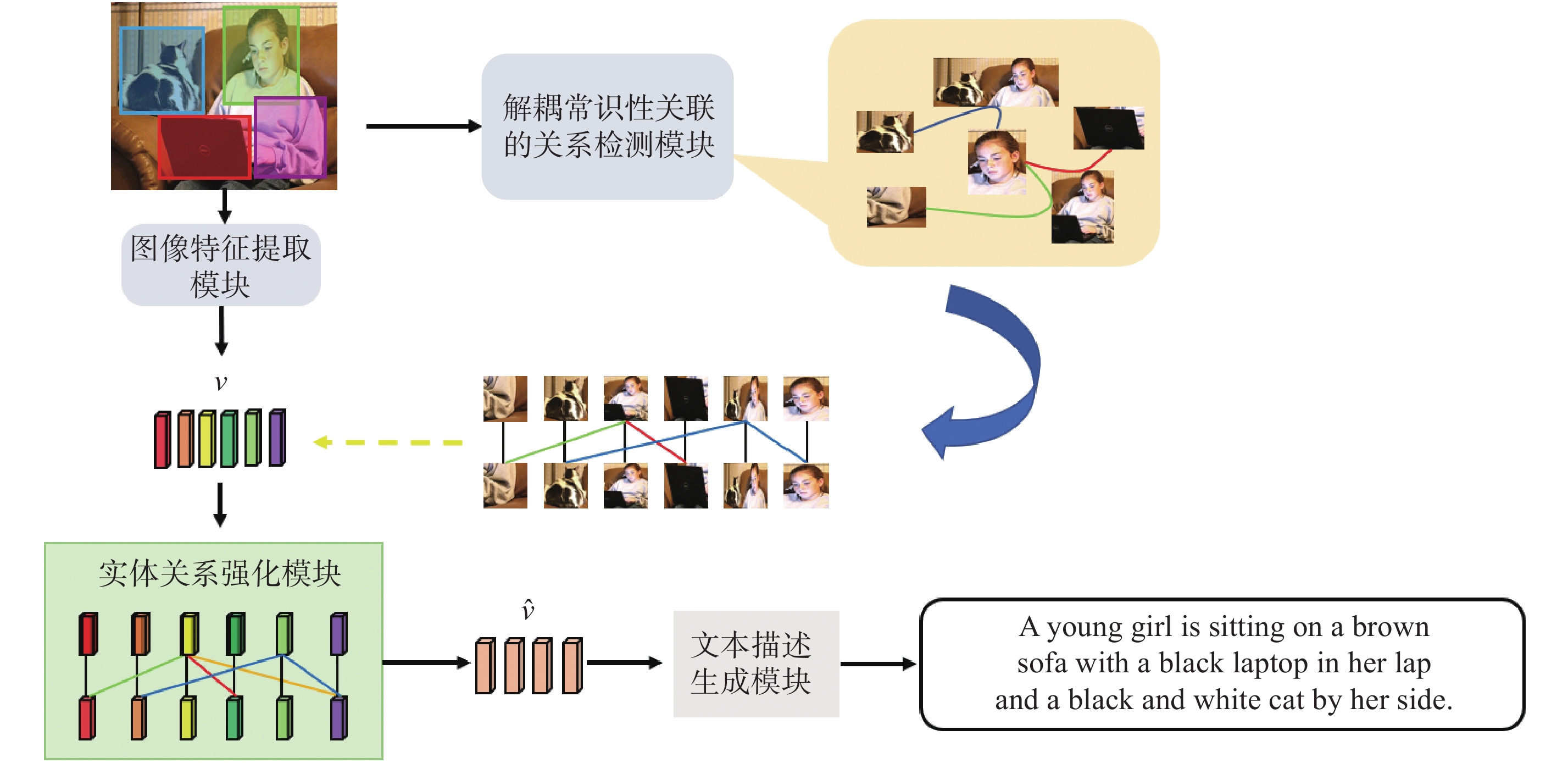
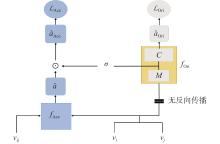
Fig.2
A relationship detection module that decouples commonsense associations"
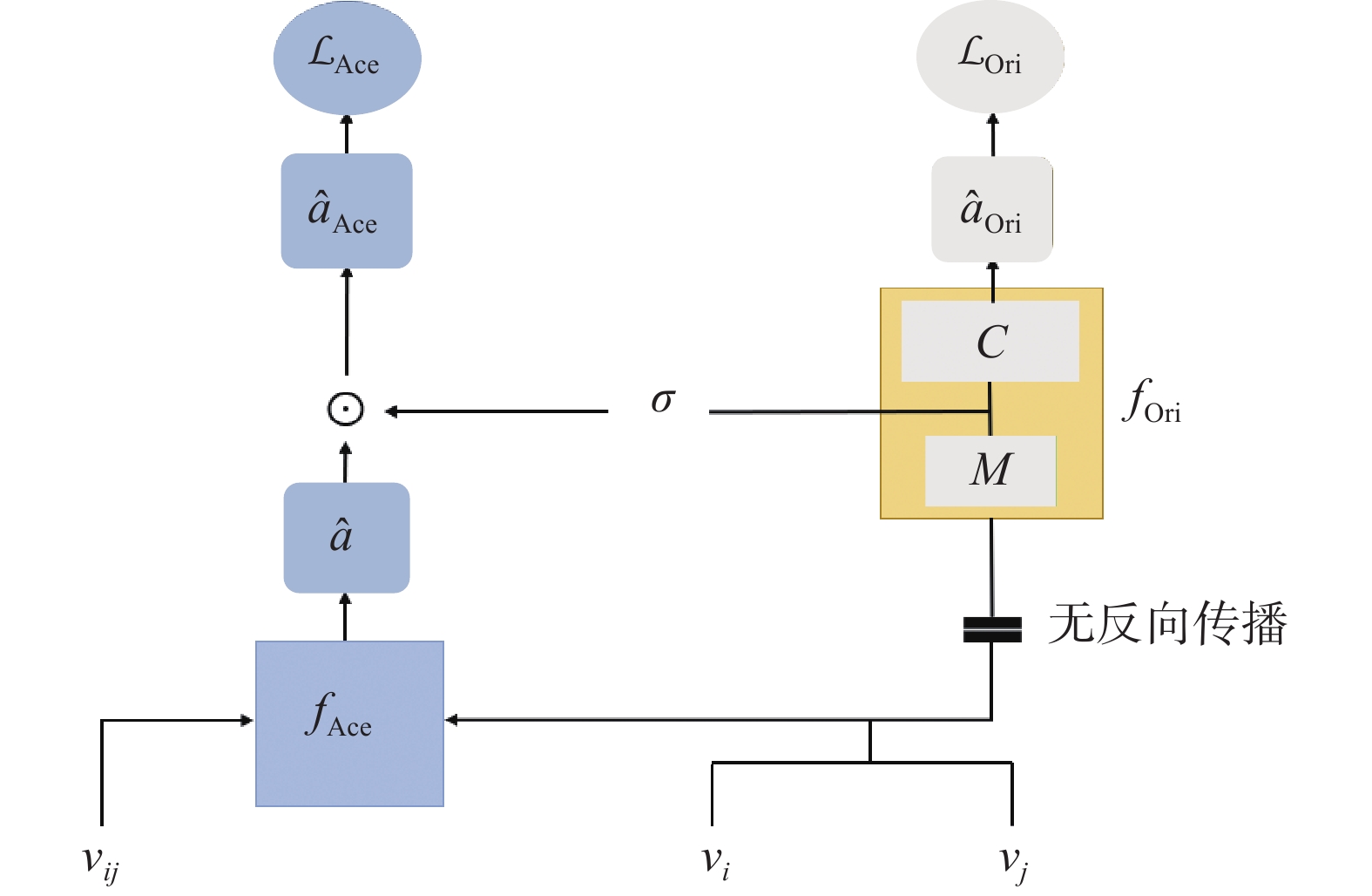
Fig.3
Training strategy for the relation detection module"
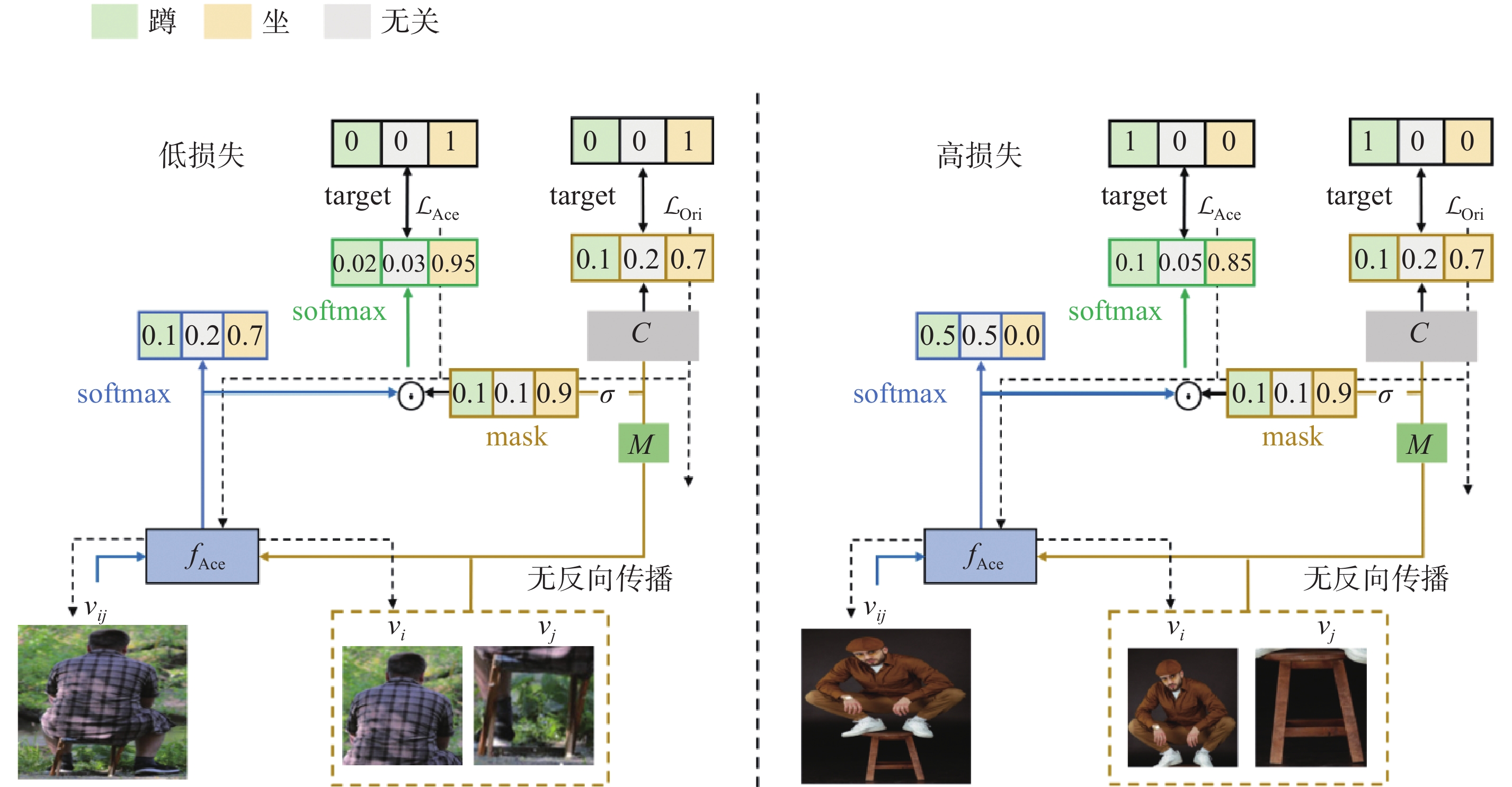
Table 1
Experimental environment configuration"
| 实验环境 | 环境配置 |
| 操作系统 | Ubuntu 18.04.6 |
| CPU (central processing unit) | Intel Xeon Gold 6226R |
| GPU (graphics processing unit) | RTX 3090 24 GB |
| 内存 | 64 GB |
| 编程语言 | Python 3.8 |
| 深度学习框架 | Pytorch 1.11 |
Table 2
Performance comparison of models on MS-COCO"
| 模型 | BLEU-1 | BLEU-4 | METEOR | ROUGE | CIDEr | SPICE |
| UP-Down | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 |
| SGAE | 80.8 | 38.4 | 28.4 | 58.6 | 127.8 | 22.1 |
| AoANet | 80.8 | 39.1 | 29.1 | 59.1 | 130.3 | 22.7 |
| 80.8 | 39.1 | 29.2 | 58.6 | 131.2 | 22.6 | |
| X-Transformer | 80.9 | 39.7 | 29.5 | 59.1 | 132.8 | 23.4 |
| RSNet | 81.1 | 39.3 | 29.4 | 58.8 | 133.3 | 23.0 |
| 81.1 | 39.6 | 29.6 | 59.1 | 133.5 | 23.2 | |
| 本文所提出的模型 | 81.4 | 39.6 | 29.7 | 59.3 | 133.3 | 22.8 |
Table 3
Performance comparison of ablation experiment on MS-COCO"
| 模型 | BLEU-1 | BLEU-4 | METEOR | ROUGE | CIDEr | SPICE |
| Base | 80.3 | 38.1 | 28.8 | 58.0 | 129.6 | 22.2 |
| Base + Ori + Att | 80.4 | 38.4 | 28.8 | 58.3 | 129.9 | 22.3 |
| Base + Ace + Att | 80.7 | 38.9 | 29.3 | 59.2 | 133.0 | 22.7 |
| Base + Ori + Ers | 80.9 | 39.0 | 29.2 | 58.8 | 132.7 | 22.5 |
| Base + Ace + Ers | 81.4 | 39.6 | 29.7 | 59.3 | 133.3 | 22.8 |

Fig.4
Visualization of the model’s attention distribution"

Table 4
Manual evaluation results for describing quality"
| 模型 | 一致性 | 完整性 | 流畅性 | 细致性 |
| 人工标注 | 4.54 | 4.20 | 4.61 | 3.72 |
| Transformer | 4.20 | 4.06 | 4.33 | 3.44 |
| 本文所提出的模型 | 4.33 | 4.17 | 4.47 | 3.56 |

Fig.5
Human evaluation examples"

Table 5
Manual evaluation results of random sampling"
| 样品 | 模型 | 一致性 | 完整性 | 流畅性 | 细致性 |
| 人工标注 | 4.1 | 4.7 | 4.6 | 4.0 | |
| Transformer | 3.0 | 4.5 | 4.8 | 4.1 | |
| 本文所提出的模型 | 4.2 | 4.8 | 4.8 | 4.4 | |
| 人工标注 | 4.6 | 4.6 | 4.3 | 3.1 | |
| Transformer | 3.6 | 4.2 | 4.1 | 3.3 | |
| 本文所提出的模型 | 4.7 | 4.6 | 4.0 | 4.0 | |
| 人工标注 | 4.7 | 4.2 | 3.9 | 3.2 | |
| Transformer | 2.9 | 3.8 | 4.5 | 2.3 | |
| 本文所提出的模型 | 4.3 | 4.0 | 4.6 | 3.1 |
| 1 | STEFANINI M, CORNIA M, BARALDI L, et al.. From show to tell: A survey on deep learning-based image captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (1): 539- 559. |
| 2 | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2. 2014: 3104-3112. |
| 3 | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: A neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3156-3164. |
| 4 | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6077-6086. |
| 5 | LI G, ZHU L, LIU P, et al. Entangled transformer for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8928-8937. |
| 6 | HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: Transforming objects into words [J]. Advances in Neural Information Processing Systems, 2019: 14733-14745. |
| 7 | XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention [C]// International Conference on Machine Learning. 2015: 2048-2057. |
| 8 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010. |
| 9 | HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 4634-4643. |
| 10 | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10578-10587. |
| 11 | PAN Y W, YAO T, LI Y H, et al. X-Linear attention networks for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10971-10980. |
| 12 | ZHANG X, SUN X, LUO Y, et al. RSTNet: Captioning with adaptive attention on visual and non-visual words [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15465-15474. |
| 13 | ZENG P P, ZHANG H N, SONG J K, et al. ${\cal{S}}^2 $ transformer for image captioning [C]// Proceedings of the International Joint Conferences on Artificial Intelligence. 2022: 12675-12684. |
| 14 | YANG X, TANG K, ZHANG H, et al. Autoencoding scene graphs for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 10685-10694. |
| 15 | LUO Y, JI J, SUN X, et al. Dual-level collaborative transformer for image captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2021: 2286-2293. |
| 16 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: Adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 375-383. |
| 17 | HU R H, SINGH A, DARRELL T, et al. Iterative answer prediction with pointer augmented multimodal transformers for textVQA [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9992-10002. |
| 18 | GAO J, MENG X, WANG S, et al. Masked non-autoregressive image captioning [EB/OL]. (2019-06-03)[2023-01-03]. https://arxiv.org/abs/1906.00717.pdf. |
| 19 | FEI Z. Iterative back modification for faster image captioning [C]// Proceedings of the 28th ACM International Conference on Multimedia. 2020: 3182-3190. |
| 20 | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 7008-7024. |
| 21 | FENG Y, MA L, LIU W, et al. Unsupervised image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 4125-4134. |
| 22 | GU J, JOTY S, CAI J, et al. Unpaired image captioning via scene graph alignments [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 10323-10332. |
| 23 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. 2021: 8748-8763. |
| 24 | JOHNSON J, KARPATHY A, LI F F. DenseCap: Fully convolutional localization networks for dense captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4565-4574. |
| 25 | YANG L, TANG K, YANG J, et al. Dense captioning with joint inference and visual context [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2193-2202. |
| 26 | LI X, JIANG S, HAN J. Learning object context for dense captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2019: 8650-8657. |
| 27 | CORNIA M, BARALDI L, CUCCHIARA R. Show, control and tell: A framework for generating controllable and grounded captions [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8307-8316. |
| 28 | ZHENG Y, LI Y, WANG S. Intention oriented image captions with guiding objects [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8395-8404. |
| 29 | CHEN S, JIN Q, WANG P, et al. Say as you wish: Fine-grained control of image caption generation with abstract scene graphs [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9962-9971. |
| 30 | CHEN L, JIANG Z, XIAO J, et al. Human-like controllable image captioning with verb-specific semantic roles [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 16846-16856. |
| 31 | LI X R, XU C X, WANG X X, et al.. COCO-CN for cross-lingual image tagging, captioning, and retrieval. IEEE Transactions on Multimedia, 2019, 21 (9): 2347- 2360. |
| 32 | LAN W, LI X, DONG J. Fluency-guided cross-lingual image captioning [C]// Proceedings of the 25th ACM International Conference on Multimedia. 2017: 1549-1557. |
| 33 | SONG Y, CHEN S, ZHAO Y, et al. Unpaired cross-lingual image caption generation with self-supervised rewards [C]// Proceedings of the 27th ACM International Conference on Multimedia. 2019: 784-792. |
| 34 | GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision. 2015: 1440-1448. |
| 35 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context [C]// Computer Vision-ECCV 2014. 2014: 740-755. |
| 36 | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3128-3137. |
| 37 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002: 311-318. |
| 38 | BANERJEE S, LAVIE A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments [C]// Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005: 65-72. |
| 39 | LIN C Y. ROUGE: A package for automatic evaluation of summaries [C]// Proceedings of the Workshop on Text Summarization Branches Out. 2004: 74-81. |
| 40 | VEDANTAM R, LAWRENCE C, PARIKH D. CIDEr: Consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 4566-4575. |
| 41 | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: Semantic propositional image caption evaluation [C]// Computer Vision-ECCV 2016. 2016: 382-398. |
| [1] | Chang WANG, Dan MA, Huarong XU, Panfeng CHEN, Mei CHEN, Hui LI. SA-MGKT: Multi-graph knowledge tracing method based on self-attention [J]. Journal of East China Normal University(Natural Science), 2024, 2024(5): 20-31. |
| [2] | Luping FENG, Liye SHI, Wen WU, Jun ZHENG, Wenxin HU, Wei ZHENG. Collaborative stranger review-based recommendation [J]. Journal of East China Normal University(Natural Science), 2024, 2024(2): 53-64. |
| [3] | Daojia CHEN, Zhiyun CHEN. Hierarchical description-aware personalized recommendation system [J]. Journal of East China Normal University(Natural Science), 2023, 2023(6): 73-84. |
| [4] | Lulu JIANG, Siqi SUN, Haidong ZOU, Lina LU, Rui FENG. Diabetic retinopathy grading based on dual-view image feature fusion [J]. Journal of East China Normal University(Natural Science), 2023, 2023(6): 39-48. |
| [5] | Zhishang DUAN, Yi RAN, Duliang LYU, Jie QI, Jiachen ZHONG, Peisen YUAN. Identifying electricity theft based on residual network and depthwise separable convolution enhanced self attention [J]. Journal of East China Normal University(Natural Science), 2023, 2023(5): 193-204. |
| [6] | Jin GE, Xuesong LU. Automatic generation of Web front-end code based on UI images [J]. Journal of East China Normal University(Natural Science), 2023, 2023(5): 100-109. |
| [7] | Zhaoyang WU, Jiali MAO. Research on travel time prediction based on neural network [J]. Journal of East China Normal University(Natural Science), 2023, 2023(2): 106-118. |
| [8] | Genmei TONG, Min ZHU. Bi-directional long short-term memory and bi-directional gated attention networks for text classification [J]. Journal of East China Normal University(Natural Science), 2022, 2022(2): 67-75. |
| [9] | Yuting HUANGFU, Liying LI, Haizhou WANG, Fuke SHEN, Tongquan WEI. Enabling self-attention based multi-feature anomaly detection and classification of network traffic [J]. Journal of East China Normal University(Natural Science), 2021, 2021(6): 161-173. |
| [10] | Yanchun LIANG, Ailian FANG. Chinese text relation extraction based on a multi-channel convolutional neural network [J]. Journal of East China Normal University(Natural Science), 2021, 2021(3): 96-104. |
| [11] | LI Xiaochang, CHEN Bei, DONG Qiwen, LU Xuesong. Discovering traveling companions using autoencoders [J]. Journal of East China Normal University(Natural Science), 2020, 2020(5): 179-188. |
| [12] | WANG Junhao, LUO Yifeng. Enriching image descriptions by fusing fine-grained semantic features with a transformer [J]. Journal of East China Normal University(Natural Science), 2020, 2020(5): 56-67. |
| [13] | FU Yu, LI You, LIN Yu-ming, ZHOU Ya. Self-attention based neural networks for product titles compression [J]. Journal of East China Normal University(Natural Sc, 2019, 2019(5): 113-122,167. |
| [14] | YANG Dong-ming, YANG Da-wei, GU Hang, HONG Dao-cheng, GAO Ming, WANG Ye. Research on knowledge point relationship extraction for elementary mathematics [J]. Journal of East China Normal University(Natural Sc, 2019, 2019(5): 53-65. |
| [15] | WANG Guo-liang, CHEN Meng-nan, CHEN Lei. An end-to-end Chinese speech synthesis scheme based on Tacotron 2 [J]. Journal of East China Normal University(Natural Sc, 2019, 2019(4): 111-119. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||